学校要求手动用python实现lasso回归,我把随即出来的数据集换成学校给的数据之后那根红色的拟合线就出不来了,那根黄色的线性回归拟合现正常,想知道是哪里出现了问题
问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
import numpy as np
from matplotlib import pyplot as plt
import sklearn.datasets
import pandas as pd
df = pd.read_excel(r'C:\Users\AORUS\Desktop\test2.xlsx')
#生成100个一元回归数据集
#x, y = sklearn.datasets.make_regression(n_features=1, noise=5, random_state=2020)下面我换成了自己的数据
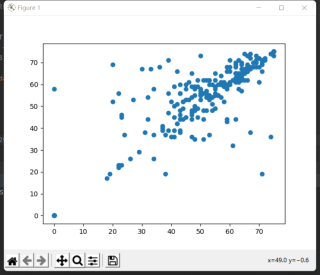
x = df['T2C_attarchment_F_sum'].values.reshape(-1,1)
y = df['T2C_attarchment_M_sum'].values
plt.scatter(x, y)
plt.show()
#加5个异常数据
a = np.linspace(1,2,5).reshape(-1,1)
b = np.array([350,380,410,430,480])
#生成新的数据集
x_1 = np.r_[x, a]
y_1 = np.r_[y, b]
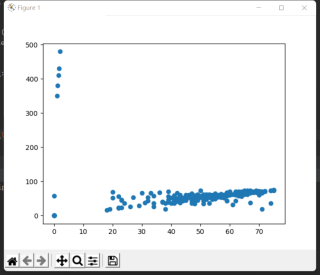
plt.scatter(x_1, y_1)
plt.show()
class normal():
def init(self):
pass
def fit(self, x, y):
m = x.shape[0]
X = np.concatenate((np.ones((m, 1)), x), axis=1)
xMat = np.mat(X)
yMat = np.mat(y.reshape(-1, 1))
xTx = xMat.T * xMat
# xTx.I为xTx的逆矩阵
ws = xTx.I * xMat.T * yMat
# 返回参数
return ws
import copy
def CoordinateDescent(x, y, epochs, learning_rate, Lambda):
m = x.shape[0]
X = np.concatenate((np.ones((m, 1)), x), axis=1)
xMat = np.mat(X)
yMat = np.mat(y.reshape(-1, 1))
w = np.ones(X.shape[1]).reshape(-1, 1)
for n in range(epochs):
out_w = copy.copy(w)
for i, item in enumerate(w):
# 在每一个W值上找到使损失函数收敛的点
for j in range(epochs):
h = xMat * w
gradient = xMat[:, i].T * (h - yMat) / m + Lambda * np.sign(w[i])
w[i] = w[i] - gradient * learning_rate
if abs(gradient) < 1e-3:
break
out_w = np.array(list(map(lambda x: abs(x) < 1e-3, out_w - w)))
if out_w.all():
break
return w
w = CoordinateDescent(x_1, y_1,epochs=250
,learning_rate=0.001,Lambda=0)
print(w)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
clf1 =normal()
#拟合原始数据
w1 = clf1.fit(x,y)
print(w1)
#预测数据
y_pred = x * w1[1] + w1[0]
#计算新的拟合值
y_1_pred = x_1 * w[1] + w[0]
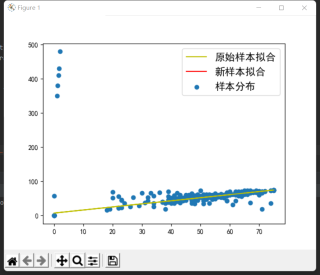
ax1= plt.subplot()
ax1.scatter(x_1,y_1,label='样本分布')
ax1.plot(x,y_pred,c='y',label='原始样本拟合')
ax1.plot(x_1,y_1_pred,c='r',label='新样本拟合')
ax1.legend(prop = {'size':15}) #此参数改变标签字号的大小
plt.show()
#我自己测试发现gradient 输出一直为【nun】
方法一:你按照文章中的方法修改Lambda。大概率是因为你的Lambda不对
方法二:把异常值改小点。
就是下面的部分:
#加5个异常数据,为什么这么加,大家自己看一下生成的x,y的样子
a = np.linspace(1,2,5).reshape(-1,1)
b = np.array([350,380,410,430,480])
建议过滤一下异常值
可能是异常点比较多的缘故
感觉红线出不来是不是异常值的问题呀?可不可以先进行异常检测,如果是异常值就不参与拟合😂
加个判断,原始样本和新样本,生成原始和新做测试
根据题主的最后一张图,可以看到左上角是存在一些异常点的
建议您先对数据做一下预处理
将异常点进行处理,再重新进行拟合
先把异常值处理了吧,不处理异常值你这咋做?
还有代码是从哪里搬的?多数你网上看的结果出来不一样是版本差异导致的。
有些细节不对,详见这篇文章,望采纳
https://blog.csdn.net/weixin_44700798/article/details/110690015
谢谢你的浏览
你的梯度是空是你要检查的问题,所以y_1_pred 是空导致没画出来
异常点估计比较多导致的,先进行数据清洗然后再回归试试
直接一句话搞定 df[~pd.isnull(df)]或者df=df.fillna(0)
方便发一下数据集吗?