Python爬虫requests反还内容与网页内容不相同
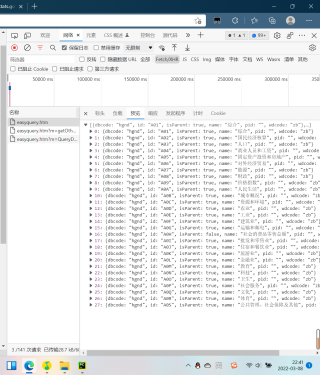
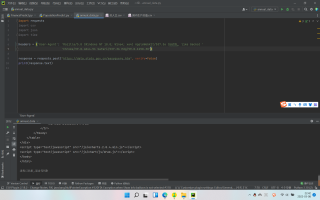
从网络预览可以看到,内容应该是一个列表,使用标头里的请求网址之后,返还的却是一个网页源码,这是为什么呢?
看一下网页里内容是啥,无关内容就是被反爬了,因为这是ajax请求,你直接抓报请求,header头部可能会反爬,有时还要加cookie,referer,csrf等
数据应该是动态加载的,图片上看数据是JSON数据。把response. text ,换成 response.json() 再打印看看
这些数据是动态请求的,你要找到所请求的api接口,直接访问这个页面是没用的
url写错了,html
还有是get请求而不是post