按照查询条件,分别把 表#tb02 的 w1~11 替换成对应的数字,并每一行从小到大排序
---> 已知数据
if object_id('[tempdb]..#tb') is not null drop table #tb;
go
create table #tb (id int,w1 INT,w2 INT,w3 INT,w4 INT,w5 INT,w6 INT,w7 INT,w8 INT,w9 INT,w10 INT,w11 INT) ;
go
insert into #tb -- select * from #tb
select '101','91','2','84','35','78','10','17','40','36','27','59'
---> 查询条件
if object_id('[tempdb]..#tb02') is not null drop table #tb02;
go
create table #tb02 (id int,n1 INT,n2 INT,n3 INT,n4 INT,n5 INT,n6 INT,n7 INT,n8 INT,n9 INT,n10 INT,n11 INT) ;
go
insert into #tb02 -- select * from #tb02
select '301','w2','w5','w9','','','','','','','',''
union all select '302','w1','w5','w6','w7','w8','w9','w10','w11','','',''
union all select '303','w2','w4','w6','w8','w10','w11','','','','',''
union all select '304','w1','w2','w3','w4','w5','w6','w7','w8','w9','w10','w11'
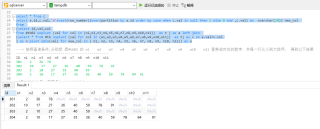
---> 按照查询条件,分别把 表#tb02 的 w1 w2 w3 w4 w5 w6 w7 w8 w9 w10 w11 替换成对应的数字,并每一行从小到大排序, 得到以下结果
------------------------------------------------
ID n1 n2 n3 n4 n5 n6 n7 n8 n9 n10 n11
301 2 36 78
302 10 17 27 36 40 59 78 91
303 2 10 27 35 40 59
304 2 10 17 27 35 36 40 59 78 84 91
不是这样的结果(原因是每一行没有排序)
-------------------------------------------------
ID n1 n2 n3 n4 n5 n6 n7 n8 n9 n10 n11
301 2 78 36
302 91 78 10 17 40 36 27 59
303 2 35 10 40 27 59
304 91 2 84 35 78 10 17 40 36 27 59
sql来了
select * from (
select a.id,c.val,'n'+cast(row_number()over(partition by a.id order by case when c.val is null then 1 else 0 end ,c.val) as nvarchar(10)) new_col
from
(select id,val,col
from #tb02 unpivot (val for col in (n1,n2,n3,n4,n5,n6,n7,n8,n9,n10,n11)) as t ) as a left join
(select * from #tb unpivot (val for col in (w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11)) as t) as c on a.val=c.col
) as n pivot (min(val) for new_col in ( n1, n2, n3, n4, n5, n6, n7, n8, n9, n10, n11)) as o
除了你曾经提出的这些问题以外,我是真没见过拿数据库做这种事的。
这些问题是你自己想出来的还是有什么实际应用场景?
没看懂哎
用sql搞的话不合适,效率也很低,最好是用程序来处理文件。可以写一个处理hdfs文件的程序,先根据#tb把‘wn’转成数字,然后每行作为一个数组,在按照大小调换元素位置,然后生成文件。#tb02可以采用外部表。指定新文件的目录就行了。