SQL如何根据某字段包含的数据主键(某主键,某主键)分组求和
两张表:
CREATE TABLE `hr_share_browsing_history` (
`id` bigint(20) NOT NULL COMMENT '主键',
`share_id` bigint(20) NULL DEFAULT NULL COMMENT '知识id',
`jobnumber` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '员工工号',
`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '员工姓名',
`dept_id` bigint(20) NULL DEFAULT NULL COMMENT '组织部门',
`gkjd` int(11) NULL DEFAULT NULL COMMENT '观看进度',
`gksc` datetime(0) NULL DEFAULT NULL COMMENT '观看时长',
`gkrq` datetime(0) NULL DEFAULT NULL COMMENT '观看日期',
`score` int(11) NULL DEFAULT NULL COMMENT '评分',
`create_time` datetime(0) NULL DEFAULT NULL COMMENT '创建时间',
`update_time` datetime(0) NULL DEFAULT NULL COMMENT '修改时间',
`create_by` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '创建人',
PRIMARY KEY (`id`) USING BTREE,
INDEX `Index_share`(`share_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '知识分享浏览记录表' ROW_FORMAT = Dynamic;
CREATE TABLE `hr_share_series` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`title_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '系列标题',
`type_id` bigint(20) NULL DEFAULT NULL COMMENT '知识类别',
`sub_type_id` bigint(20) NULL DEFAULT NULL COMMENT '细分类别',
`type` int(11) NULL DEFAULT NULL COMMENT '类型,1:视频,2:文档,3:音频',
`share_id` varchar(500) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '知识id,集合',
`create_time` datetime(0) NULL DEFAULT NULL COMMENT '创建时间',
`create_by` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '创建人',
`is_delete` int(11) NULL DEFAULT 0 COMMENT '是否删除,1:是,0:否',
`update_time` datetime(0) NULL DEFAULT NULL COMMENT '修改时间',
`collect_number` int(11) NULL DEFAULT 0 COMMENT '收藏数量',
PRIMARY KEY (`id`) USING BTREE,
INDEX `Index_share_id`(`share_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 57 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '知识系列表' ROW_FORMAT = Dynamic;
知识系列表hr_share_series中的字段share_id存的是知识分享浏览记录表hr_share_browsing_history的知识Id 'share_id',是String格式用逗号','分隔,如"98,123,946,4315,46541"这种
需求是想根据hr_share_series中的share_id累加所有在这个String里的hr_share_browsing_history中的条数+AVG(打分score),如下:
这条是根据share_id分组累加求平均,就是每个share_id的数据
SELECT share_id, avg( score ) AS score, count(*) AS read_number FROM hr_share_browsing_history GROUP BY share_id
想展示的是这样:
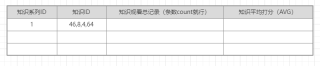
说一下是什么数据库吧,指定分隔符的字符串转列在很多数据库都算是个比较麻烦的事,你指定了数据库后我再按你指定数据库的语法来写一下
---模拟数据
insert into hr_share_browsing_history (ID,share_id,jobnumber) values (1,1,'A');
insert into hr_share_browsing_history (ID,share_id,jobnumber) values (2,2,'A');
insert into hr_share_browsing_history (ID,share_id,jobnumber) values (3,3,'A');
insert into hr_share_browsing_history (ID,share_id,jobnumber) values (4,1,'B');
insert into hr_share_browsing_history (ID,share_id,jobnumber) values (5,2,'B');
insert into hr_share_browsing_history (ID,share_id,jobnumber) values (6,5,'B');
INSERT INTO hr_share_series(id,title_name,share_id) VALUES(1,'XXX','1,2,3');
INSERT INTO hr_share_series(id,title_name,share_id) VALUES(2,'YYY','5');
---一个系列里的知识个数不能大于700个,否则需要自己建一个序列来替代mysql.help_topic 这张表
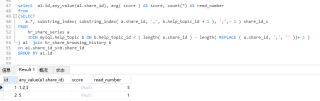
select a1.id,any_value(a1.share_id), avg( score ) AS score, count(*) AS read_number
from
(SELECT
a.*, substring_index( substring_index( a.share_id, ',', b.help_topic_id + 1 ), ',',- 1 ) share_id_s
FROM
hr_share_series a
JOIN mysql.help_topic b ON b.help_topic_id < ( length( a.share_id ) - length( REPLACE ( a.share_id, ',', '' ))+ 1 )
) a1 join hr_share_browsing_history b
on a1.share_id_s=b.share_id
GROUP BY a1.id
SELECT
substring_index( substring_index( a.share_id, ',', b.help_topic_id + 1 ), ',',- 1 )
FROM
hr_share_series a
JOIN mysql.help_topic b ON b.help_topic_id < ( length( a.share_id ) - length( REPLACE ( a.share_id, ',', '' ))+ 1 )
ORDER BY
a.ID
如果是ORACLE的话可以使用 INSTR 函数查询 "98,123,946,4315,46541" 中的逗号的位置,通过位置计算字符长度,使用截取函数
SUBSTR 来分段截取里面的ID,例如
SELECT SUBSTR(X,1,A-1) A,SUBSTR(X,A+1,B-A-1) B,SUBSTR(X,B+1,C-B-1) C ,SUBSTR(X,C+1,D-C-1) D,SUBSTR(X,D+1,E-D) E FROM (
SELECT A X,instr(A,',',1,1) A,instr(A,',',1,2) B,instr(A,',',1,3) C,instr(A,',',1,4) D,length(a) E FROM (
SELECT '98,12,43,124,442' A FROM DUAL))
最后SELECT 单个字段UNION ALL起来 ,这样就组成了单个ID 的数据。然后再考虑连接条件,还有截取字符的时候要考虑ID的个数,考虑最长的ID能截取多少个,短的截取完后多了一些空值,需要过滤掉。这是想到的一点思路。
SELECT
(
SELECT
AVG( score ) AS '平均分'
FROM
hr_share_browsing_history A
WHERE
FIND_IN_SET( share_id, B.share_id )) AS '平均分',
B.*
FROM hr_share_series B