批量提取多个TXT 文本中指定内容 导出为一个TXT
多个TXT 批量提取文本中的某些内容 导出为一个txt 文本或者别的格式 该怎么实现
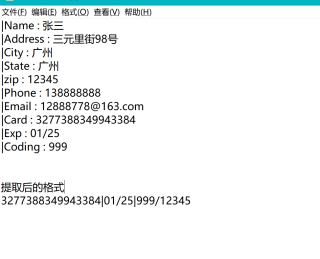
os.listdir(path)遍历文件夹中多个TXT 用正则提取文本中的指定内容
你题目的解答代码如下:
#-*- coding:utf-8 -*-
import os
import re
rs = ""
path = r"E:/xxx" #读取txt文件的目录路径
FileNames=os.listdir(path)
for fn in FileNames:
if fn.endswith('.txt'):
fullfilename=os.path.join(path,fn)
print(fullfilename)
with open(fullfilename, 'r', encoding='utf-8') as fileObj:
text = fileObj.read()
card = re.findall(r'Card:(.+)',text)
exp = re.findall(r'Exp:(.+)',text)
coding = re.findall(r'Coding:(.+)',text)
zip = re.findall(r'zip:(.+)',text)
if len(card)>0 and len(exp)>0 and len(coding)>0 and len(zip)>0:
rs += card[0] + "|" + exp[0] + "|" + coding[0] + "|" +zip[0] + "\n"
print(rs)
with open(r'data.txt', 'w', encoding='utf-8') as fileObj:
fileObj.write(rs)
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

读取每一行的内容,然后以 :分割每行的内容,冒号两边的内容存为一个字典,最后再拼接你想要的内容
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632