java 使用dom3c解析xml文件问题,多级节点解析
读取xml文件,
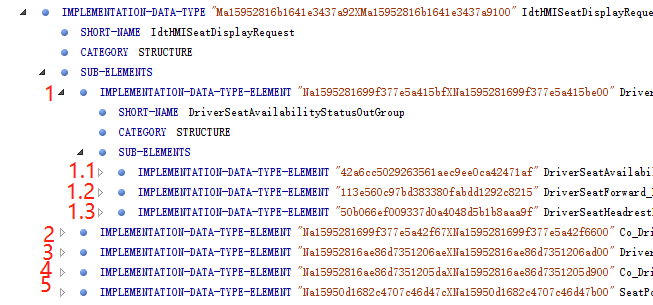
获取如下标签的NodeList,
NodeList impList = doc.getElementsByTagName("IMPLEMENTATION-DATA-TYPE");
for(int i = 0; i < impList.getLength(); i++) {
Element impElement = (Element) impList.item(i);
NodeList impSubList = impElement.getElementsByTagName("IMPLEMENTATION-DATA-TYPE-ELEMENT");
System.out.println("impSubList legth= " + impSubList.getLength());
}
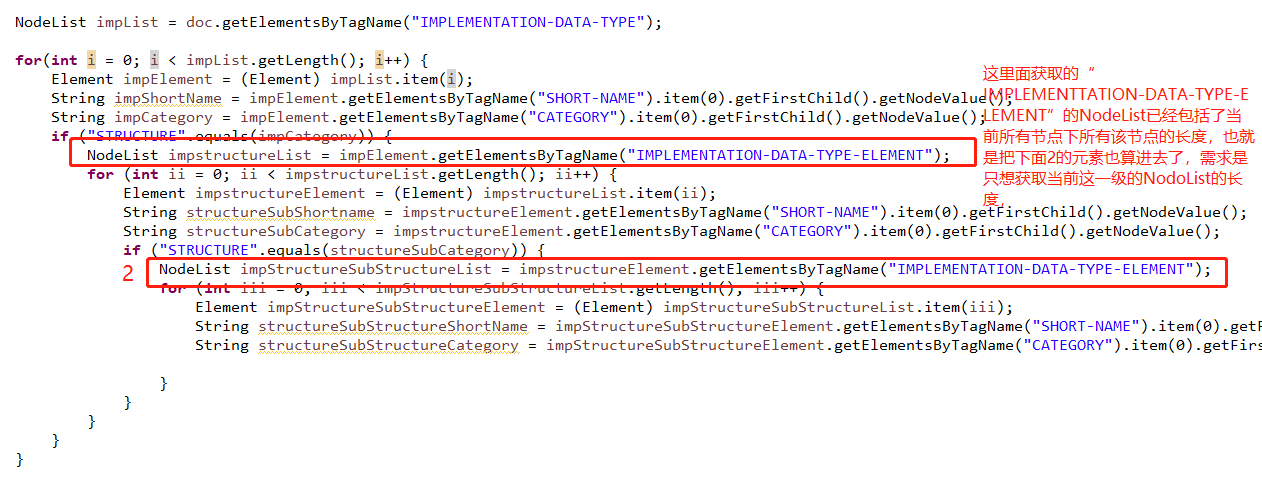
我想做到输出的impSubList legth=5,但是实际输出的长度是这个节点下所有的这个便签的长度。怎么一级一级解析下去 获取长度?
直接上代码
package cn.next;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import org.w3c.dom.Text;
public class Test {
public static void ReadTreeStructure(NodeList nodes) {
for (int i = 0; i < nodes.getLength(); i++) {
if (nodes.item(i).getNodeType() == Node.ELEMENT_NODE) {
System.out.print(nodes.item(i).getNodeName() + " ");
String value = ((Text) (nodes.item(i).getFirstChild())).getData().trim();
if (value.getBytes().length != 0) {
System.out.print(value);
}
System.out.println();
}
//如果节点还有子节点,递归调用
if (nodes.item(i).getChildNodes().getLength() != 0) {
ReadTreeStructure(nodes.item(i).getChildNodes());
}
}
}
public static void main(String[] args) {
DocumentBuilderFactory docbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder docb = docbf.newDocumentBuilder();
Document doc = docb.parse("***.xml");
NodeList nodes = doc.getElementsByTagName("IMPLEMENTATION-DATA-TYPE");
ReadTreeStructure(nodes);
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
设置一个count变量 进行判断 然后累加count
package com.test;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomXML {
public static void main(String[] args) {
try {
File file = new File("e:/People.xml");
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(file);
Element element = document.getDocumentElement();
List<People> peopleList = new ArrayList<People>();
NodeList peopleNodes = element.getElementsByTagName("People");
for(int i=0;i<peopleNodes.getLength();i++){
People people = new People();
Element peopleElement = (Element) peopleNodes.item(i);
people.setId(peopleElement.getAttribute("id"));
NodeList childPeopleNodes = peopleElement.getChildNodes();
for(int j=0;j<childPeopleNodes.getLength();j++){
//DOM解析时候注意子节点前面的空格也会被解析
if(childPeopleNodes.item(j) instanceof Element){
Element childPeopleElement = (Element) childPeopleNodes.item(j);
if(childPeopleElement.getNodeType()==Node.ELEMENT_NODE){
if(childPeopleElement.getNodeName().equals("Name")){
people.setEnglishName(childPeopleElement.getAttribute("en"));
people.setName(childPeopleElement.getTextContent());
}
else if(childPeopleElement.getNodeName().equals("Age")){
people.setAge(childPeopleElement.getTextContent());
}
}
}
}
peopleList.add(people);
}
for(People people : peopleList){
System.out.println(people.getId()+"\t"+people.getName()+"\t"+people.getEnglishName()+"\t"+people.getAge());
}
} catch (Exception e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
要不用dom4j解析吧,可以直接拿子节点的列表,而不是所有的子孙节点