利用#开窗函数#的问题,如何解决?#面试题#
计算月累计,年累计数据
table1 为各个产品的到天的销售数量数据。
注意:数据在日期维度是不连续的。
Table1(业务数据表)此表为固定1月与2月就销售了如下量
| PERIOD_CODE(日期) | PL_NAME(产品名称) | AMOUNT(当日销量) |
| 20210101 | 冰箱 | 10 |
| 20210102 | 冰箱 | 2 |
| 20210103 | 冷柜 | 1 |
| 20210105 | 冰箱 | 1 |
| 20210105 | 冷柜 | 1 |
| 20210205 | 冰箱 | 1 |
| 20210205 | 冷柜 | 1 |
Table2(日期维表) 此表有20210101—20210228所有日期及标识
| PERIOD_CODE(日期) | PERIOD_MONTH(日期标识) |
| 20210101 | 1 |
| 20210102 | 1 |
| ...... | ...... |
| 20210201 | 2 |
| ...... | ...... |
| 20210228 | 2 |
通过以上两张表得出Table3(结果表)
Tabel3 (结果表)
输出结果为连续日期,20210101—20210228的当日销量,月累销量,年累销量
| PERIOD_CODE | PL_NAME | AMOUNT_DAY(当日数) | AMOUNT_MONTH(月累计) | AMOUNT_YEAR(年累计) |
| 20210101 | 冰箱 | 10 | 10 | 10 |
| 20210102 | 冰箱 | 2 | 12 | 12 |
| 20210103 | 冰箱 | 0 | 12 | 12 |
| 20210104 | 冰箱 | 0 | 12 | 12 |
| 20210105 | 冰箱 | 1 | 13 | 13 |
| ...... | ...... | ...... | ...... | ...... |
| 20210131 | 冰箱 | 0 | 13 | 13 |
| 20210201 | 冰箱 | 0 | 0 | 13 |
| 20210202 | 冰箱 | 0 | 0 | 13 |
| 20210203 | 冰箱 | 0 | 0 | 13 |
| 20210204 | 冰箱 | 0 | 0 | 13 |
| 20210205 | 冰箱 | 1 | 1 | 14 |
| ...... | ...... | ...... | ...... | ...... |
| 20210228 | 冰箱 | 0 | 1 | 14 |
| 20210101 | 冷柜 | 0 | 0 | 0 |
| 20210102 | 冷柜 | 0 | 0 | 0 |
| 20210103 | 冷柜 | 1 | 1 | 1 |
| 20210104 | 冷柜 | 0 | 1 | 1 |
| 20210105 | 冷柜 | 1 | 2 | 2 |
| ...... | ...... | ...... | ...... | ...... |
| 20210131 | 冷柜 | 0 | 2 | 2 |
| 20210201 | 冷柜 | 0 | 0 | 2 |
| 20210202 | 冷柜 | 0 | 0 | 2 |
| 20210203 | 冷柜 | 0 | 0 | 2 |
| 20210204 | 冷柜 | 0 | 0 | 2 |
| 20210205 | 冷柜 | 1 | 1 | 3 |
| ...... | ...... | ...... | ...... | ...... |
| 20210228 | 冷柜 | 0 | 1 | 3 |
你的月累计和年累计的确是用开窗函数没问题,用order by 或者滑动窗口都行。
但是重点是,无法保证每个产品在每天都有记录,这个点不是用开窗函数来解决,而应该用递归来处理,但这就要看你的数据库是啥了,不同数据库的写法不一样。另外,还可以通过产品列表和日期维表来无条件关联,得到两两任意组合的一个完整数据,此时可以用这个数据为主,左关联其他的数据再来进行开窗函数计算,但这明显不如递归优雅。
开窗函数不能增加不存在的记录,所以只能先构建一个不存在的记录了,不用递归sql大概长这样
with t1 as (
select * from
(select distinct pl_name from table1) a,table2 b
)
select
t1.PERIOD_CODE ,
t1.PL_NAME ,
nvl( t2.amount,0) AMOUNT_day,
sum(nvl( t2.amount,0)) over(partition by substr(PERIOD_CODE,1,6) order by PERIOD_CODE) AMOUNT_MONTH ,
sum(nvl( t2.amount,0)) over(partition by substr(PERIOD_CODE,1,4) order by PERIOD_CODE) AMOUNT_YEAR
from t1 left join table1 t2 on t1.PERIOD_CODE=t2.PERIOD_CODE and t1.pl_name=t2.pl_name
之所以没用PERIOD_MONTH这个字段,是怕数据里有跨年的,光这个月份字段无法进行准确分组,因此从日期里重新截取年月和年
如果sqlserver不支持这种窗口,那么可以使用移动窗口,从第一行到当前行 ,
sum(isnull( t2.amount,0)) over(partition by PERIOD_MONTH,t1.PL_name order by PERIOD_CODE rows between unbounded preceding and current row)
关于递归的话,我举个类似的例子吧
with t as (
select 1 dt ,'a' name,1 amount union all
select 2 dt ,'a' name,1 amount union all
select 3 dt ,'a' name,1 amount union all
select 5 dt ,'a' name,1 amount union all
select 1 dt ,'b' name,1 amount union all
select 2 dt ,'b' name,1 amount
),
x as(
select t.*,row_number() over(partition by name order by dt) rn from t) ,
cte as (select dt,name,amount,amount amount_sum from x where rn=1
union all
select cte.dt+1,cte.name,
isnull((select x.amount from x where cte.dt+1=x.dt and cte.name=x.name),0),
isnull((select x.amount from x where cte.dt+1=x.dt and cte.name=x.name),0)+cte.amount_sum from cte where cte.dt+1<=5
)
select * from cte order by name,dt
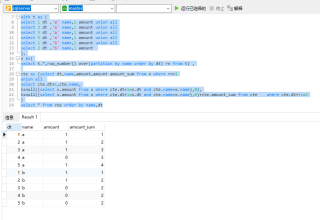
假设dt是日期,可以看到原始数据不连续,但通过cte中的递归,实现了数据的补齐,并且还可以同时把累加一起做了,而且,最后的数据行数可能还会比笛卡尔积的要少,因为这个对于每个产品只会从有销售的第一天开始统计,避免了很多无效数据
开窗可以拿到格式相同但只能统计有的数据,这种没数据日期统计为零的不会,插个眼看后面有没有大佬
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632