爬虫时遇到了奇奇怪怪的字符!字节or?
我是看了一个爬虫案例,发现网站已经搬家就去爬了另一个类似的网站,结果打印出页面源代码是这种奇奇怪怪的字符。。

注:不是编码的问题。因为如果编码不对,那它只有中文不正常,其他都是正常的
字节or外星文?(实在没得猜了)
——分割线——
再粘贴一张有编码的截图,截图上是utf-8
但是gbk也是错的
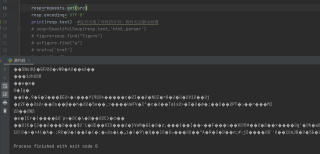
这个应该是编码问题 如果不是编码问题 那么是可以正常显示 HTML 标签的
可能是打开的软件编码问题
UTF-8转gbk就是这样会出现乱码情况
网站多少
加上encoding:utf-8试试
如果是html的话,应该得加上
这个好像是html解读没有上面那个东西的代码会产生的问题。