从cvs文件中读取某时间段的数据时出现:TypeError: 'module' object is not subscriptable
问题遇到的现象和发生背景
从cvs文件中读取0-500s之间的速度数据,运行结果出现问题。
求各位朋友们帮助!
问题相关代码,请勿粘贴截图
col=df.columns.values
df.columns=[x.strip() for x in col] ###首行文字去前后空格
df.drop_duplicates(subset=['gpstime'],keep='first',inplace=True) ##删除gps时间重复的列
####数据预处理—————排序
df_paixu=df.sort_values(by=['gpstime'],ascending=[1])
df_paixu=df_paixu.reset_index(drop=True) ###重置排序后数列的index
df_paixu['gpstime']=(df_paixu['gpstime']-min(df_paixu['gpstime']))/1000
#####数据预处理————数据单位转化为标准单位及百分比
df_paixu['speed']=(df_paixu['speed'])/100/3.6 #车速单位km/h
##读取1-500s时间段内的数据
open_time='0'
close_time='500'
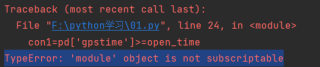
con1=pd['gpstime']>=open_time
con2=pd['gpstime']<close_time
pd[con1&con2]
##画图
x = df.loc[:,'gpstime']# 读取csv文件中的某两列
y = df.loc[:,'speed']
plt.plot(x,y,color='r', label=u'1路') # 绘制x,y的折线图
plt.savefig(r'C:\Users\歪歪\Desktop\工况预估\1.jpg')#保存图片
plt.show() # 显示折线图
你pd 是什么对象?
pd 应该是 pandas 模块的别名吧, 你应该改成 df_paixu 吧
con1=df_paixu['gpstime']>=open_time
con2=df_paixu['gpstime']<close_time
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

con1=pd['gpstime']题主怎么直接用了pd呢
您不是用的import pandas as pd嘛?
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632