关于字符串占用字节大小问题
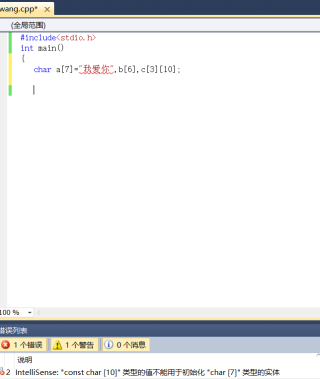
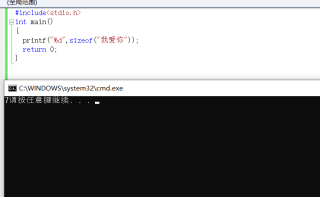
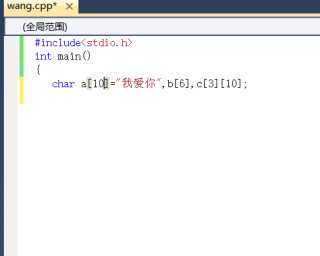
网上说汉字占用两个字节,那我的第一张图片为什么不正确呢,如果是数字的大小是两个字节无法保存到大小为一个字节的字符数组元素中,那为什么第三张图片又可以了呢
UTF-8是变长字符编码。当汉字按UTF-8编码表示时,一个汉字可能占2个、3个、甚至4个字节。
当你定义一个字符串数组时,如果你不确定字符串的长度,可以忽略数组的大小,编译器会自动计算数组大小。
char a[] = "我爱你";
因为字符串后面会有\0作为结尾符,所以7个肯定不行,可以用strlen看一下字符串大小
可能不同的编译器直接也有差异(这里是对汉字编码的支持吧),我用vs2019测试,却是可以的。
另外,对汉字编码,不一定都只占两个字节,这是可以肯定的,也要注意的。