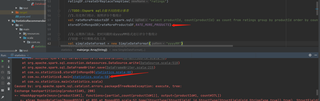
Exception in thread "main" org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
Exchange rangepartitioning(count#23L DESC NULLS LAST, 200)
+- *HashAggregate(keys=[productId#1], functions=[count(productId#1)], output=[productId#1, count#23L])
+- Exchange hashpartitioning(productId#1, 200)
+- *HashAggregate(keys=[productId#1], functions=[partial_count(productId#1)], output=[productId#1, count#37L])
+- *Scan MongoRelation(MongoRDD[0] at RDD at MongoRDD.scala:52,Some(StructType(StructField(_id,StructType(StructField(oid,StringType,true)),true), StructField(productId,IntegerType,true), StructField(sorce,DoubleType,true), StructField(timestamp,IntegerType,true), StructField(userid,IntegerType,true)))) [productId#1] ReadSchema: struct<productId:int>
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.execution.exchange.ShuffleExchange.doExecute(ShuffleExchange.scala:112)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:135)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:113)
at org.apache.spark.sql.execution.InputAdapter.inputRDDs(WholeStageCodegenExec.scala:235)
at org.apache.spark.sql.execution.SortExec.inputRDDs(SortExec.scala:121)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:368)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:135)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:113)
at org.apache.spark.sql.execution.DeserializeToObjectExec.doExecute(objects.scala:90)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:135)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:113)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:92)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:92)
at org.apache.spark.sql.Dataset.rdd$lzycompute(Dataset.scala:2570)
at org.apache.spark.sql.Dataset.rdd(Dataset.scala:2567)
at com.mongodb.spark.MongoSpark$.save(MongoSpark.scala:162)
at com.mongodb.spark.sql.DefaultSource.createRelation(DefaultSource.scala:90)
at org.apache.spark.sql.execution.datasources.DataSource.write(DataSource.scala:518)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:215)
at com.xu.statistics$.storeDFInMongoDB(statistics.scala:88)
at com.xu.statistics$.main(statistics.scala:58)
at com.xu.statistics.main(statistics.scala)
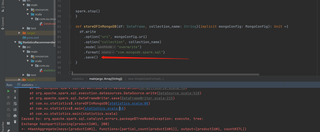
Caused by: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
Exchange hashpartitioning(productId#1, 200)
+- *HashAggregate(keys=[productId#1], functions=[partial_count(productId#1)], output=[productId#1, count#37L])
+- *Scan MongoRelation(MongoRDD[0] at RDD at MongoRDD.scala:52,Some(StructType(StructField(_id,StructType(StructField(oid,StringType,true)),true), StructField(productId,IntegerType,true), StructField(sorce,DoubleType,true), StructField(timestamp,IntegerType,true), StructField(userid,IntegerType,true)))) [productId#1] ReadSchema: struct<productId:int>
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.execution.exchange.ShuffleExchange.doExecute(ShuffleExchange.scala:112)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:135)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:113)
at org.apache.spark.sql.execution.InputAdapter.inputRDDs(WholeStageCodegenExec.scala:235)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.inputRDDs(HashAggregateExec.scala:141)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:368)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:114)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:135)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:113)
at org.apache.spark.sql.execution.exchange.ShuffleExchange.prepareShuffleDependency(ShuffleExchange.scala:85)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$$anonfun$doExecute$1.apply(ShuffleExchange.scala:121)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$$anonfun$doExecute$1.apply(ShuffleExchange.scala:112)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
... 34 more
Caused by: java.lang.UnsupportedOperationException: The DefaultMongoPartitioner requires MongoDB >= 3.2
at com.mongodb.spark.rdd.partitioner.DefaultMongoPartitioner.partitions(DefaultMongoPartitioner.scala:58)
at com.mongodb.spark.rdd.MongoRDD.getPartitions(MongoRDD.scala:137)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.ShuffleDependency.<init>(Dependency.scala:91)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$.prepareShuffleDependency(ShuffleExchange.scala:261)
at org.apache.spark.sql.execution.exchange.ShuffleExchange.prepareShuffleDependency(ShuffleExchange.scala:84)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$$anonfun$doExecute$1.apply(ShuffleExchange.scala:121)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$$anonfun$doExecute$1.apply(ShuffleExchange.scala:112)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)