首页
编程
java
php
前端
首页
编程
java
php
前端
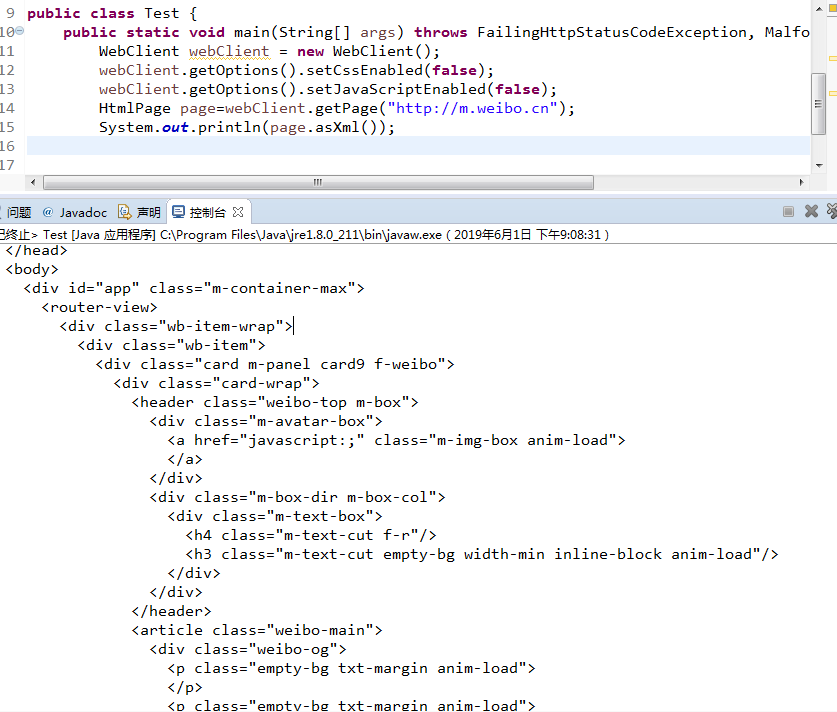
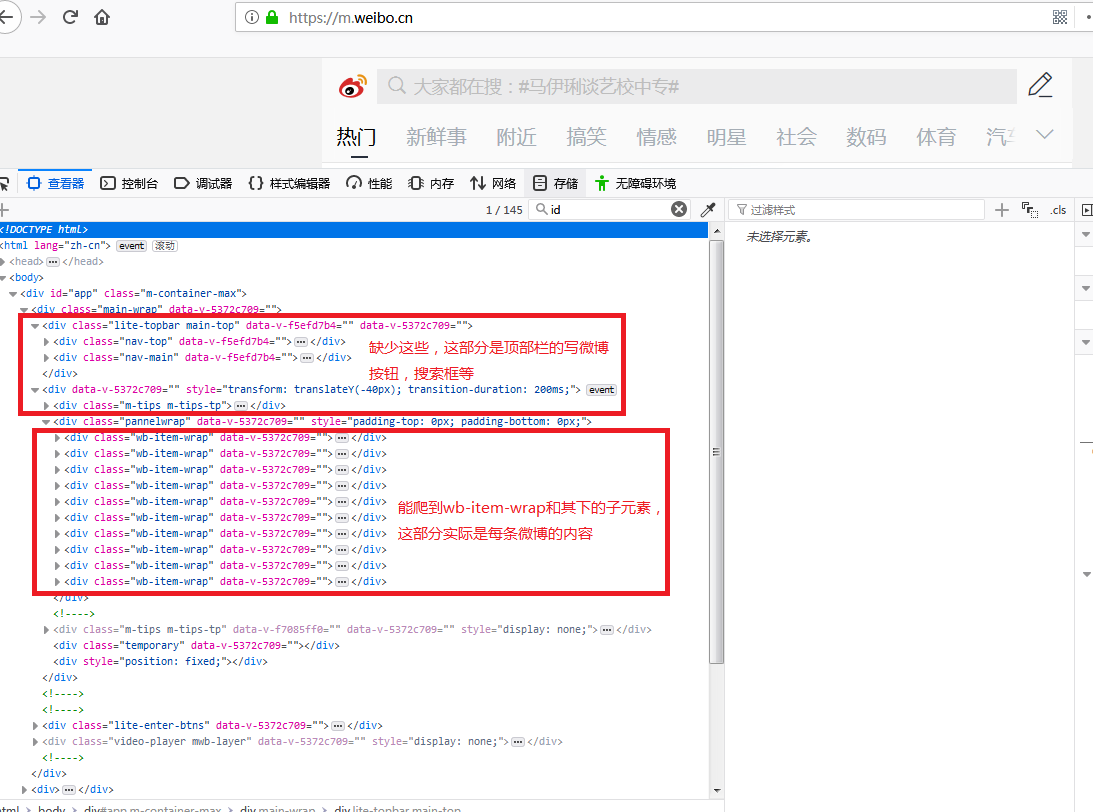
HtmlUnit爬网页不完整,缺少一些标签该如何解决?
我用HtmlUnit中的WebClient.getPage()爬微博手机网页,但输出后发现比用浏览器查看的源码要少一部分标签,请教一下这是什么原因呢?有没有什么解决办法。
点击展开全文