oracle 千万级数据group by或distinct如何优化
1.问题
oracle 11g版本,一张用户参加活动的流水表,就参加某一活动的所有用户数目,进行去重统计。采用group by或distinct去重时,发现磁盘一直100%,速度过慢。
2.sql执行结果图
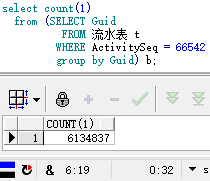
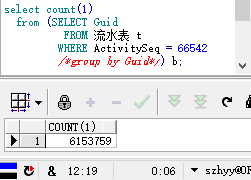
上图去重耗时=32s,下图不去重耗时=6s(相关字段均已建立索引,且索引未失效)。
3.sql解析计划图
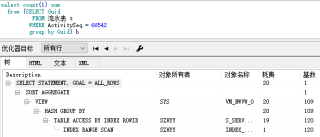
4.请问
我发现耗时出现在group by、count(1)统计,导致的大量磁盘读写上,这种sql查询要如何优化呢?
或者有什么别的设计方法,可以避开这种问题呢?
这sql优化我搞不出来了,改成代码里选用redis的典型应用场景解决了😂
如果不需要聚合计算的话(sum,count等),distinct是比group by效率高点的,尝试不用子查询,直接select count(distinct guid) from ....
如果还是不理想,那么我建议使用中间临时表,将符合条件的数据,只要guid字段,放入临时表中,再对临时表进行select count(distinct guid) from ....处理。
select /*+parallel (t,8)*/ count(distinct guid) from 流水表 t where ActivitySeq =66542;
select /*+parallel (t,16)*/ count(distinct guid) from 流水表 t where ActivitySeq =66542;