python怎么把excel中的等级化为分数
我要进行文字描述的数值化,要把风险等级这一列的等级转化为相应的分数,非常危险-9.5分,危险-7.5分,中等-5分,轻微-2.5分,非常轻微-0.5分,python代码要怎么写,能详细一点吗
同1楼的意见,可以通过字典,再利用几个库,然后再看情况慢慢优化代码,以下粗略的可以参考一下
import pandas as pd
from openpyxl import load_workbook
filename = 'C:/Users/Administrator/PycharmProjects/EXCELread/test.xlsx' # 你想要读取的文件路径名
dict_trans = {'非常危险': '9.5分', '危险': '7.5分', '中等': '5分', '轻微': '2.5分', '非常轻微': '0.5分'} # 创建字典,为后续转换做准备
df = pd.read_excel(filename, sheet_name='转化') # 读取excel文件为df(DataFrame),假设所在的sheet为‘转化’
for key in dict_trans:
df['风险等级'].replace(key, dict_trans[key], inplace=True) # 在'风险等级'列,根据字典dict_trans进行替换
# 以下为仅修改‘风险等级’的内容,不会修改excel文件的其他部分
book = load_workbook(filename)
writer = pd.ExcelWriter(filename, engine='openpyxl')
writer.book = book
writer.sheets = {ws.title: ws for ws in book.worksheets}
df.to_excel(writer, sheet_name='转化', index=False) # 仅在sheet_name='转化',即sheet‘转化’进行修改转化
writer.close()
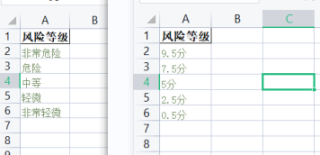
使用pandas的apply函数直接转换即可,代码如下:
import pandas as pd
df=pd.read_excel('t2.xlsx')
df['分数'] = df['风险等级'].apply(lambda x: -9.5 if x == '非常危险' else -7.5 if x =='危险' else -5 if x == '中等' else -2.5 if x == '轻微' else -0.5)
print(df)
df.to_excel('t2_1.xlsx',index=False)
运行结果:
风险等级 分数
0 非常危险 -9.5
1 危险 -7.5
2 中等 -5.0
3 轻微 -2.5
4 非常轻微 -0.5
如有帮助,请点采纳。
写个字典不就好了么,没办法更详细了吧