有关byte数组转int32的计算过程的一些疑问
下面的一段代码是用来将byte[]转为int数值的,在里面我用注释标记了两个问题:
1. 为什么startIndex是4的整数倍就可以用下面这种方式得到int值?
2. *((int*)pbyte) 这句代码具体做了哪些操作?数据发生了哪些变化?
希望有大佬给解释一下,谢谢!
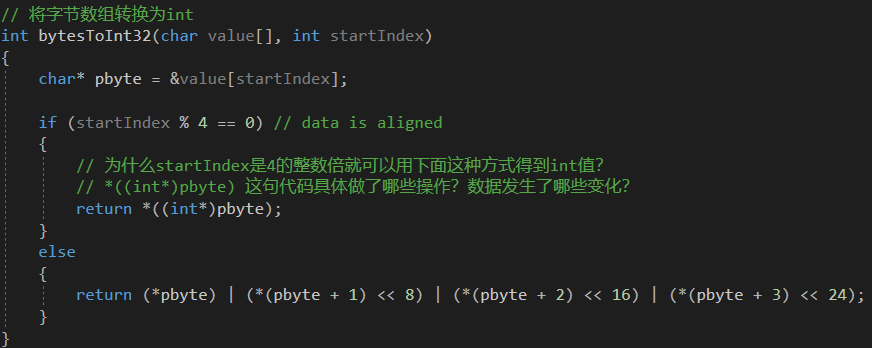
// 将字节数组转换为int
int bytesToInt32(char value[], int startIndex)
{
char* pbyte = &value[startIndex];
if (startIndex % 4 == 0) // data is aligned
{
// 为什么startIndex是4的整数倍就可以用下面这种方式得到int值?
// *((int*)pbyte) 这句代码具体做了哪些操作?数据发生了哪些变化?
return *((int*)pbyte);
}
else
{
return (*pbyte) | (*(pbyte + 1) << 8) | (*(pbyte + 2) << 16) | (*(pbyte + 3) << 24);
}
}
你这个函数的作用是将value数组的第startIndex字节数据转换成int类型,不管有没有if (startIndex % 4 == 0)这句话,都是将value数组的第startIndex字节数据转换成int类型。else里面返回的int类型一定是小端模式的,比如pbyte 后面4个字节分别是0x12,0x34,0x56,0x78那么else里面返回一定是0x78563412.但是if里面就不一定了,如果使用的芯片是小端模式,那么return ((int)pbyte); 返回的还是0x78563412,但是如果你使用的芯片是大端模式,这时return ((int)pbyte);返回的数据就不是0x78563412了。
而是0x12345678;*((int*)pbyte这句话的意思是将pbyte指针强制转换成int类型的指针,然后再取这个int类型指针的值,就是将alue[startIndex]往后读4字节的数据再转换成int型。
我测试了下,无论是否对齐,都可以直接得到结果,那个判断是多余的
#include <stdio.h>
int bytesToInt32(char value[], int startIndex)
{
char* pbyte = &value[startIndex];
return *((int*)pbyte);
}
int main()
{
char arr[10];
//在x86处理器上,低位在前面
arr[1] = 123;
arr[2] = 0;
arr[3] = 0;
arr[4] = 0;
int x = bytesToInt32(arr, 1);
printf("%d", x);
return 0;
}
这句代码:
// char* pbyte = &value[startIndex];
*((int*)pbyte)
是不是会自动的从value[startIndex]往后读4字节的数据再转换成int?
/**
* byte数组中取int数值,本方法适用于(低位在前,高位在后)的顺序,和和intToBytes()配套使用
*
* @param src
* byte数组
* @param offset
* 从数组的第offset位开始
* @return int数值
*/
public static int bytesToInt(byte[] src, int offset) {
int value;
value = (int) ((src[offset] & 0xFF)
| ((src[offset+1] & 0xFF)<<8)
| ((src[offset+2] & 0xFF)<<16)
| ((src[offset+3] & 0xFF)<<24));
return value;
}
之前有学过c++,工作以后一直学的java,贴一段代码,一起学习下。
指针类型应该和指向数据类型保持一致的,当pbyte由char变为int时,内容也发生了变化。一个int32需要4个char的转换。