爬虫报错TypeError: stat: path should be string, bytes, os.PathLike or integer, not function,如何解决?
问题遇到的现象和发生背景
用PyCharm爬取https://www.dieniao.com的免费代理IP时,出现错误TypeError: stat: path should be string, bytes, os.PathLike or integer, not function。用的环境是Anaconda
问题相关代码,请勿粘贴截图
#免费获取代理IP
import requests
import urllib3
from lxml import etree
import pandas as pd
from sqlalchemy import false
ip_list = [] #创建保存IP地址的列表
urllib3.disable_warnings()
def get_ip(url,headers):
#发送网络请求
response = requests.get(url,headers=headers,verify = false)
response.encoding = 'utf-8' #设置编码方式
if response.status_code == 200: #判断请求是否成功
html = etree.HTML(response.text) #解析HTML
#获取所有带有IP的li标签
li_all = html.xpath('//li[@class="f-list col-lg-12 col-md-12 col-sm-12 col-xs-12"]')
for i in li_all: #遍历每行内容
ip = i.xpath('span[@class="f-address"]/text()')[0] #获取IP
port = i.xpath('span[@class="f-port"]/text()')[0] #获取端口
ip_list.append(ip+':'+port) #将IP与端口组合并添加至列表当中
print('代理ip为:', ip, '对应端口为:', port)
#头部信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if __name__ == '__main__':
ip_table = pd.DataFrame(columns=['ip']) #创建临时表格数据
for i in range(1,5):
#获取免费代理IP的请求地址
url = 'https://www.dieniao.com/FreeProxy/{page}.html'.format(page=i)
get_ip(url,headers)
ip_table['ip'] = ip_list #将提取的IP保存至Excel文件的IP列
#生成xlsx文件
ip_table.to_excel('ip.xlsx', sheet_name='data')
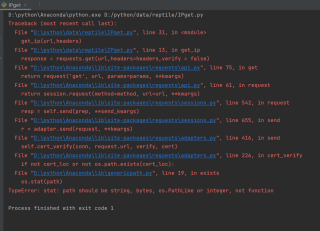
想让程序正常运行,爬取到IP
这一行写错了参数值,是False不是false,f要大写,
response = requests.get(url, headers=headers, verify=False)
另外函数get_ip要写上return ip_list返回数据。修改代码如下:
import requests
import urllib3
from lxml import etree
import pandas as pd
from sqlalchemy import false
ip_list = [] # 创建保存IP地址的列表
urllib3.disable_warnings()
def get_ip(url, headers):
#发送网络请求
response = requests.get(url, headers=headers, verify=False)
response.encoding = 'utf-8' # 设置编码方式
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析HTML
#获取所有带有IP的li标签
li_all = html.xpath(
'//li[@class="f-list col-lg-12 col-md-12 col-sm-12 col-xs-12"]')
for i in li_all: # 遍历每行内容
ip = i.xpath('span[@class="f-address"]/text()')[0] # 获取IP
port = i.xpath('span[@class="f-port"]/text()')[0] # 获取端口
ip_list.append(ip+':'+port) # 将IP与端口组合并添加至列表当中
print('代理ip为:', ip, '对应端口为:', port)
return ip_list
#头部信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if __name__ == '__main__':
ip_table = pd.DataFrame(columns=['ip']) # 创建临时表格数据
iplst=[]
for i in range(1, 5):
#获取免费代理IP的请求地址
url = 'https://www.dieniao.com/FreeProxy/{page}.html'.format(page=i)
ip_list=get_ip(url, headers)
iplst+=ip_list
ip_table['ip'] = iplst # 将提取的IP保存至Excel文件的IP列
#生成xlsx文件
ip_table.to_excel('ip.xlsx', sheet_name='data')
如对你有帮助,请点击采纳按钮。
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632