用python读取多个csv表指定数据写入一个表中
我想用python 合并一组表格,麻烦给写可直接用的代码
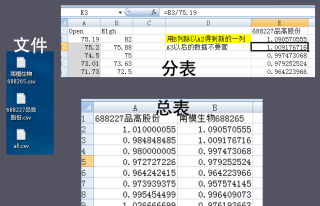
目录D:/001 文件下有多个cvs表(表1到表?),
把第二列(B2到B?,数量不固定)除以固定值A2,
得到新的列合并输出在all.csv中,放同目录下
第一行输出表格文件名,原表第一行数据不需要,
如图分表第3列是需要的生成的数据合并到总表
下面是一组参考代码,用来改改可能快一点
import pandas as pd
import os
# 获取当前路径
cwd = os.getcwd()
# 要拼接的文件夹及其完整路径,注不要包含中文
# 待读取批量csv的文件夹
read_path = 'data_Q1_2018'
# 待保存的合并后的csv的文件夹
save_path = 'data_Q1_2018_merge'
# 待保存的合并后的csv
save_name = 'Modified.csv'
# 修改当前工作目录
os.chdir(read_path)
# 将该文件夹下的所有文件名存入列表
csv_name_list = os.listdir()
# 读取第一个CSV文件并包含表头,用于后续的csv文件拼接
df = pd.read_csv( csv_name_list[0])
# 读取第一个CSV文件并保存
df.to_csv( cwd + '\\' + save_path + '\\' + save_name , encoding="utf_8",index=False)
# 循环遍历列表中各个CSV文件名,并完成文件拼接
for i in range(1,18):
df = pd.read_csv( csv_name_list[i] )
df.to_csv(cwd + '\\' + save_path + '\\' + save_name ,encoding="utf_8",index=False, header=False, mode='a+')
import pandas as pd
import glob
import os
# 获取当前路径
cwd = os.getcwd()
# 要拼接的文件夹及其完整路径,注不要包含中文
## 待读取批量csv的文件夹
read_path = 'data_Q1_2018'
## 待保存的合并后的csv的文件夹
save_path = 'data_Q1_2018_merge'
## 待保存的合并后的csv
save_name = 'Modified.csv'
# 修改当前工作目录
os.chdir(read_path)
# 将该文件夹下的所有文件名存入列表
csv_name_list = glob.glob('*csv')
# 读取第一个CSV文件并包含表头,用于后续的csv文件拼接
df = pd.read_csv(csv_name_list[0])
tableName = os.path.splitext(csv_name_list[0])[0]
df[tableName] = df[df.columns[1]] / df.iloc[0,0]
tableList = []
tableList.append(tableName)
# # 循环遍历列表中各个CSV文件名,并完成文件拼接
for i in range(1,len(csv_name_list)):
data = pd.read_csv( csv_name_list[i] )
tableName2 = os.path.splitext(csv_name_list[i])[0]
tableList.append(tableName2)
data[tableName2] = data[data.columns[1]] / data.iloc[0,0]
df = pd.concat([df,data],axis=1)
finalData = df[tableList]
finalData.to_csv(cwd + '\\' + save_path + '\\' + save_name ,encoding="utf_8",index=False)
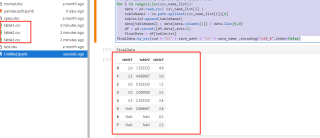
import os
import pandas as pd
# 保存的文件名称
save_name = 'all.csv'
# 保存的路径
root = 'D:\\001'
# 读取所有文件
file_names = os.listdir(root)
tableList = []
i = -1
for x in file_names:
# 遍历所有csv文件,除了all.csv
csv_file = root + "\\" + x
if (os.path.splitext(csv_file)[1] == '.csv' and x != save_name):
i += 1
tableName = os.path.splitext(x)[0]
print("读取文件:"+x)
if i == 0:
# 读取第一个CSV文件并包含表头,用于后续的csv文件拼接
df = pd.read_csv(csv_file)
df[tableName] = df[df.columns[1]] / df.iloc[0,0]
tableList.append(tableName)
if i > 0:
# 读取csv文件
a = pd.read_csv(csv_file)
tableList.append(tableName)
a[tableName] = a[a.columns[1]] / a.iloc[0,0]
df = pd.concat([df,a],axis=1)
finalData = df[tableList]
print("读取完毕")
finalData.to_csv(root + '\\' + save_name ,encoding="utf_8",index=False)
答主,按照你文案的要求写的,你试试看
你A和B的表头是什么?还是都是数字?
你的每个表的每一列哪只有一个数?
路劲写的是相对路径,你自己改或者直接在文件夹路径运行
#%% 数据处理准备工作
import os
import re
import logging
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
#%% 初始化日志文件
def init_log():
"""
初始化日志文件,若日志已存在则删除重建
"""
# 日志目录
log_dir = ".\\日志\\"
# 不存在新建
if not os.path.exists(log_dir):
os.mkdir(log_dir)
# 日志文件路径
log_file_path = log_dir + "log.txt"
# 若日志文件存在则删除
if os.path.exists(log_file_path):
os.remove(log_file_path)
# 日志格式
log_format = "%(asctime)s - %(levelname)s - %(message)s"
# 配置日志
logging.basicConfig(filename=log_file_path, level=logging.INFO, format=log_format)
#%% 获取文件路径
def get_path(dir_path):
"""
获取所有利润明细表文件路径
:param dir_path: 利润明细表文件目录
:return: 利润明细表文件路径列表
"""
# 文件路径列表
file_path_list = []
for root, dirnames, filenames in os.walk(dir_path):
for filename in filenames:
# 完整文件路径
file_path = os.path.join(root, filename)
# 入队列
file_path_list.append(file_path)
return file_path_list
file_list = get_path(".\\001\\")
#%% 加载单个文件
def load_single(file_path):
"""
加载单个FBA新品列表,提取asin列
:param file_path: FBA新品列表文件路径
:return:
"""
# 提取列
fet_cols = [0, 1]
try:
name = re.search(r"001\\(.*?).csv",file_path).group(1)
# 加载新品列表
data = pd.read_csv(file_path, usecols=fet_cols)
data[name] = data.iloc[::,1]/data.iloc[0,0]
data = data[[name]]
return data
except Exception:
logging.error("-" * 20 + "%s加载错误:" % file_path, exc_info=True)
return None
#%% 加载所有FBA新品列表
def load_all(file_path_list):
"""
加载所有FBA新品列表
:param file_path_list: 所有小组FBA新品列表文件路径
:return:
"""
# 数据列表
data_list = []
# 文件加载失败数量
load_failed_num = 0
# 遍历文件路径列表
for file_path in file_path_list:
# 加载单个小组所有订单文件
data = load_single(file_path)
# 判断是否加载失败
if data is None:
# 计数器加一
load_failed_num += 1
# 入数据列表
data_list.append(data)
# 判断是否合并数据列表
if load_failed_num > 0:
print('文件加载失败数量:%s' % load_failed_num)
else:
# 合并数据列表
result = pd.concat(data_list, axis=1)
return result
#%% 保存
def save(data):
"""
Parameters
----------
data : TYPE
DESCRIPTION.
Returns
-------
None.
"""
# 保存为文件
dir_path_1 = ".\\文件\\"
if not os.path.exists(dir_path_1):
os.makedirs(dir_path_1)
# 文件路径
file_path_1 = dir_path_1 + "test.csv"
data.to_csv(file_path_1,index=False)
#%%
if __name__=="__main__":
# 初始化日志文件
init_log()
# 所有订单文件路径列表
file_list = get_path(".\\001\\")
# 加载单个FBA新品列表
single_data = load_single(file_list[0])
# 加载所有FBA新品列表
all_data = load_all(file_list)
save(all_data)
题主,你试试看。思想就是dataframe->series->dataframe
import pandas as pd
import os
def getTargetColumn(df):
new_series = df.values[:, 1] / df.values[0, 0]
return new_series
# 获取当前路径
cwd = os.getcwd()
# 要拼接的文件夹及其完整路径,注不要包含中文
## 待读取批量csv的文件夹
read_path = 'data_Q1_2018'
## 待保存的合并后的csv的文件夹
save_path = 'data_Q1_2018_merge'
## 待保存的合并后的csv
save_name = 'Modified.csv'
# 修改当前工作目录
os.chdir(read_path)
# 将该文件夹下的所有文件名存入列表
csv_name_list = os.listdir()
length = len(csv_name_list)
# 读取第一个CSV文件并包含表头,用于后续的csv文件拼接
df = pd.read_csv(csv_name_list[0], sep="\t", header=0)
dataDict = dict()
series_1 = getTargetColumn(df)
key = os.path.splitext(csv_name_list[0])[0] # '表1'
dataDict[key] = series_1
newDataFrame = pd.DataFrame(dataDict)
# 读取第一个CSV文件并保存
newDataFrame.to_csv(cwd + '\\' + save_path + '\\' + save_name, encoding="utf_8", index=False)
# 循环遍历列表中各个CSV文件名,并完成文件拼接
for i in range(1, length):
df_Tmp = pd.read_csv(csv_name_list[i], sep="\t", header=0)
key = os.path.splitext(csv_name_list[i])[0] # '表' + str(i + 1)
dataDict_i = dict()
series_i = getTargetColumn(df_Tmp)
dataDict_i[key] = series_i
newDataFrame_i = pd.DataFrame(dataDict_i)
newDataFrame = pd.concat([newDataFrame, newDataFrame_i], axis=1)
# 建议这行提到for外面,除非你文件很多,不然没必要每次读入写入读出
newDataFrame.to_csv(cwd + '\\' + save_path + '\\' + save_name, sep="\t", encoding="utf_8", index=False)


for i in range(1,len(csv_name_list)):
data = pd.read_csv( csv_name_list[i] )
tableName2 = os.path.splitext(csv_name_list[i])[0]
tableList.append(tableName2)
data[tableName2] = data[data.columns[1]] / data.iloc[0,0]
df = pd.concat([df,data],axis=1)
finalData = df[tableList]
finalData.to_csv(cwd + '\' + save_path + '\' + save_name ,encoding="utf_8",index=False)
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632