爬虫用cookie只能爬一半怎么办?
问题遇到的现象和发生背景
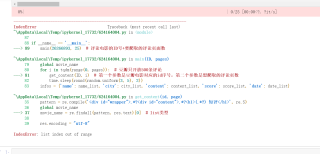
def main(ID, pages):
global movie_name
for i in tqdm(range(0, pages)): # 豆瓣只开放500条评论
get_content(ID, i) # 第一个参数是豆瓣电影对应的id序号,第二个参数是想爬取的评论页数
time.sleep(round(random.uniform(3, 5), 2))
infos = {'name': name_list, 'city': city_list, 'content': content_list, 'score': score_list, 'date': date_list}
data = pd.DataFrame(infos, columns=['name', 'city', 'content', 'score', 'date'])
data.to_csv(movie_name + ".csv") # 存储名为 电影名.csv
if name == 'main':
main(26266893, 25) # 评论电影的ID号+要爬取的评论页面数
我的解答思路和尝试过的方法
从报错信息看应该是在获取movie_name时,用正则匹配时获取值 为None,导致索引越界,可以用try/except或用if 不为空,取值索引[0]否则为“”,这样筛选一下。