python爬虫初学者,网页手动打开过才显示数据,爬虫访问没打开过的网页,爬不到数据怎么办?
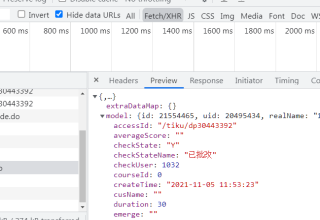
以前打开过的网页,会有js_r['model']['in']属性 ,没手动打开过得js_r['model']是空的。
下图是打开手动网页看到的。没点开过的用爬虫获取发现都是空的,这种怎么办?
import requests
import json
headers= {
'Origin': 'https://uc.educity.cn',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Cookie':''}
url='https://uc.educity.cn/ucapi/uc/paper/loadNotEndTestLog.do'
list=('30444522', '30443957', '30443392', '30442827', '30442262', '30441697', '30441132', '30440567', '30440002', '30439437', '30438872', '30438307', '30437742', '30437177', '30436612')
for s in list:
data={'tcId':s}
r=requests.post(url,headers=headers,data=data)
js_r=r.json()
if js_r['model'] != {}:
print(js_r['model']['id'])
else:
print(js_r)
将请求头的参数都设置进去,然后在独立设置cookie参数
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632