爬虫request能不能提取出正在获取的网页的url
正常都是填完参数后就能进行网页获取
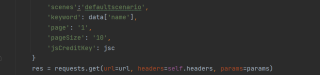
但是如果我想把该网页的url也保存下来,如果不填参数全填url的话,url会显得很臃肿而且代码也不好看,能不能提取出正在获取的网页的url呢

我JAVA的.你说的应该是request请求里面.既有URL.又有参数等,JAVA这边有个深拷贝和浅拷贝.深拷贝可以达成.python这边你看下
呃,看这样子直接在循环里print(url)就能输出你要的东西。。。如果这样就直接在循环里写进文件了呀。
正常都是填完参数后就能进行网页获取
我JAVA的.你说的应该是request请求里面.既有URL.又有参数等,JAVA这边有个深拷贝和浅拷贝.深拷贝可以达成.python这边你看下
呃,看这样子直接在循环里print(url)就能输出你要的东西。。。如果这样就直接在循环里写进文件了呀。