如何将求1NN的改写成求KNN
加载数据库等等
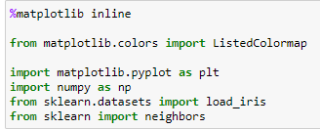
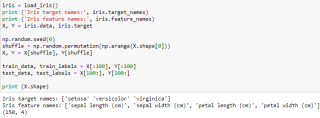
计算距离
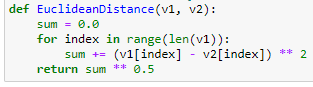
这个是求最近的1个值
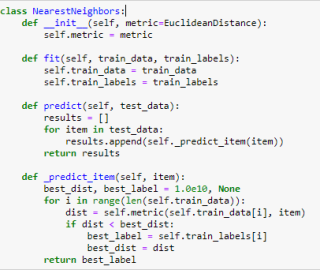
我现在想把上面求1个值改成返回K个最邻值 要如何写?
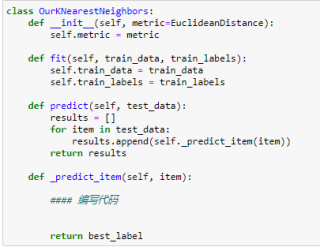
可以麻烦写下代码轮廓么
假如计算K个最近邻,在循环里面在计算dist距离时,刚开始K个循环,都要保存下来,从K+1之后,如果距离dist小于前面保存的最大的,就把它替换掉,这样代码的效率会比较高。
下面是代码, 望采纳!
def _predict_item(self, item, K):
best_labelK = []
best_distK = []
n=0
for i in range(len(train_data)):
dist = self.metric(train_data[i], item)
n = n + 1
if n<=K:
best_distK.append(dist)
best_labelK.append(self.train_labels[i])
else:
if dist < max(best_distK):
update_index = best_distK.index(max(best_distK))
best_distK(update_index) = dist
best_labelK(update_index) = self.train_labels[i]
return best_labelK
添加一个按距离从小到大排列的优先队列,遍历所有元素,依次计算每个元素与给定数据的距离,并将每个元素与其距离入队列,每当队列大小超过k时,队列末尾元素出列。当遍历结束时,这个队列里的所有元素就是你要求的kNN。
最笨的办法就是把所有值都算出来,并存在一个数组a[]中,然后数组从小到大排列,a[0]----a[k-1]就是你要的结果,
冒泡排序,存进一个list,然后遍历判断list大小,超过k就停止存入。
目前也只想到求所有值,然后进行冒泡排序,取K值。
在__init__中添加一个top_k的参数,然后距离函数需要变成双重循环计算,或者像我一样写在一起也行。
from collections import Counter
class Nearxxxx:
def __init__(self,metric,top_k):
self.k=top_k
def _predict_item(self,item):
best_dist,best_label=1.0e10,None
d=[np.sqrt(np.sum((i-self.train_data)**2)) for i in self.train_data]
nearest=np.argsort(d)
top_k=[self.train_labels[i] for i in nearest[:self.k]]
return top_k
比较常规的逻辑是先求出所有值,然后进行排序,取K值。
冒泡排序
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split as tsplit
p0, p1 = (-1,-1), (1,1)
v0, v1 = 0.8, 1.2
xs_0 = np.random.normal(loc=p0[0], scale=pow(v0,0.5), size=5000)
ys_0 = np.random.normal(loc=p0[1], scale=pow(v0,0.5), size=5000)
label_0 = np.zeros(5000, dtype=np.int32)
xs_1 = np.random.normal(loc=p1[0], scale=pow(v1,0.5), size=5000)
ys_1 = np.random.normal(loc=p1[1], scale=pow(v1,0.5), size=5000)
label_1 = np.ones(5000, dtype=np.int32)
X = np.vstack((np.stack((xs_0, ys_0), axis=1), np.stack((xs_1, ys_1), axis=1)))
y = np.hstack((label_0, label_0))
X_train, X_test, y_train, y_test = tsplit(X, y, test_size=0.1) # 拆分
m = KNeighborsClassifier() # 设置k=5
m.fit(X_train, y_train) # 训练
KNeighborsClassifier()
score = m.score(X_test, y_test) # 模型测试精度
print(score)