如何在pyhton用requests模块的get方法进行下载完整网络资源?
在pyhton用requests模块的get方法进行下载网络资源时只有一点
#请求的url
video_url = 'http://v9-xg-web-default.ixigua.com/a96ebf1d6fd505ef032eb297112c59de/61e43a53/video/tos/cn/tos-cn-o-0004/430b2a8952ea4c999669cc4f1fa8fe73/media-video-avc1/?a=1768&br=3230&bt=3230&cd=0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=&er=0&ft=arKpuqq3mw3PSYTnz7V3w-ectfuIUdOhM5&l=2022011622123501021216520804AFB879&lr=default&mime_type=video_mp4&net=0&pl=0&qs=0&rc=andlOWg6ZmhuOjMzNDczM0ApZGZlaGdlMztpNzpoOzs2O2dxMDA0cjRnczFgLS1kLS9zczIvX2NfMjA2MTUwLjM1NjA6Yw%3D%3D&vl=&vr='
response = requests.get(video_url, headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'v9-xg-web-default.ixigua.com',
'If-Modified-Since': 'Mon, 27 Dec 2021 07:05:41 GMT',
'Range': 'bytes=0-1048575',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
})
#保存视频文件
with open('视频.mp4', 'wb') as f:
f.write(response.content)
#下载的视频文件只有一点
下载的视频文件只有一点
可能是被反爬了
我尝试换不同的header
我想把视频全下载下来
你用记事本打开'视频.mp4'看看是什么内容, 如果是html或json数据就是被反爬了
可能是requests伪造的头部信息不全。
要在headers中添加抓包时的请求头求参数
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
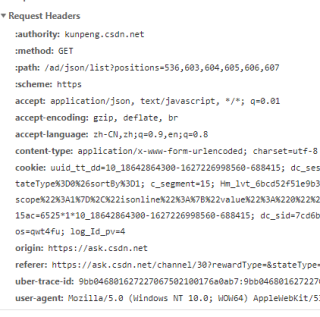
如果'视频.mp4'内容不是html或json数据,分段下载试试
video_url = 'http://v9-xg-web-default.ixigua.com/a96ebf1d6fd505ef032eb297112c59de/61e43a53/video/tos/cn/tos-cn-o-0004/430b2a8952ea4c999669cc4f1fa8fe73/media-video-avc1/?a=1768&br=3230&bt=3230&cd=0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=&er=0&ft=arKpuqq3mw3PSYTnz7V3w-ectfuIUdOhM5&l=2022011622123501021216520804AFB879&lr=default&mime_type=video_mp4&net=0&pl=0&qs=0&rc=andlOWg6ZmhuOjMzNDczM0ApZGZlaGdlMztpNzpoOzs2O2dxMDA0cjRnczFgLS1kLS9zczIvX2NfMjA2MTUwLjM1NjA6Yw%3D%3D&vl=&vr='
response = requests.get(video_url, headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'v9-xg-web-default.ixigua.com',
'If-Modified-Since': 'Mon, 27 Dec 2021 07:05:41 GMT',
'Range': 'bytes=0-1048575',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}, stream=True)
#保存视频文件
with open('视频.mp4', 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!


路径不对啊