shell脚本处理文本 特定行内容加倍
shell脚本处理文本1:
有一个文本,里面行内容有两种,一种以符号>开头,一种开头没有符号>。要求将没有符号>开头的行文本内容都倍增,就是比如行内容ABC倍增成ABCABC,行内容12345变成1234512345。以符号>开头的行内容不变。
shell脚本处理文本2:
一个文件夹data下全是这种txt文本文件,需要将这些txt文件全部按照第一个要求处理后到out文件夹下,文件名变成test-out.txt
test.txt文本举例
1
A12345
2
B12345
3
C12345
处理后的test-out.txt内容
1
A12345A12345
2
B12345B12345
3
C12345C12345
shell的也不是不可能,来作为挑战,我这次不用Python
#!/bin/bash
function read_dir(){
for file in `ls $1`
do
if [ -d $1"/"$file ]
then
read_dir $1 "/" $file
else
echo $1"/"$file >> $2
for line in `cat $1"/"$file`
do
if [[ "$line" =~ \>.* ]];then
echo "$line" >> $2
else
echo "$line$line" >> $2
fi
done
fi
done
}
read_dir $1 $2
第一个传data的位置,第二个是传out的文件名字,结果如图
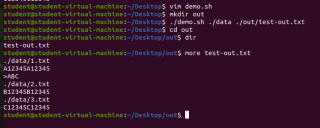
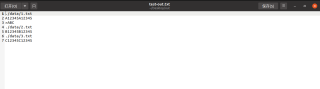
脚本1:
用法:script1 文件名
#!/bin/bash
while IFS= read -r line || [[ -n $line ]]; do
if [[ "$line" =~ \>.* ]];then
echo "$line" >> $1_tmp
else
echo "$line""$line" >> $1_tmp
fi
done < $1
mv $1_tmp $1
cat $1
脚本2:
用法:script2 输入文件夹名 输出文件夹名
#!/bin/bash
function duplicate() {
if [ ! -d $2 ]; then
mkdir $2
fi
for element in `ls $1`
do
dir_or_file=$1"/"$element
if [ -d $dir_or_file ]
then
getdir $dir_or_file
else
while IFS= read -r line || [[ -n $line ]]; do
if [[ "$line" =~ \>.* ]];then
echo "$line" >> $2"/"`echo $element | sed -r 's/(.*)\.txt/\1-out.txt/'`
else
echo "$line""$line" >> $2"/"`echo $element | sed -r 's/(.*)\.txt/\1-out.txt/'`
fi
done < $dir_or_file
fi
done
}
duplicate $1 $2
shell脚本好像不太好处理;
你可以用python试试;方便简单;
如果使用node.js写脚本还是比较简单的。