爬取boss网页为什么什么也不显示?
from lxml import etree
import requests
url='https://www.zhipin.com/job_detail/?query=python'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//div[@id="wrap"]/div[3]/div/div[3]/ul/li') #定位到
for li in li_list:
title=li.xpath('./div/div[1]/div[1]/div/div[1]/span[1]/a@title')
print(li)
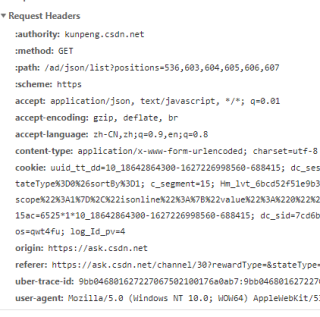
可能是requests伪造的头部信息不全。
要在headers中添加抓包时的请求头求参数
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到