如何使python保存的html文件转成pdf后打开超链接能跳转到网页以及展开隐藏内容?
使用pyhon保存'http://scp-wiki-cn.wikidot.com/scp-009' 的内容时,
发现无法正常打开超链接,同时网页中一个点击即可展开的地址也无法展开
网页中点击前后:
点击前
点击后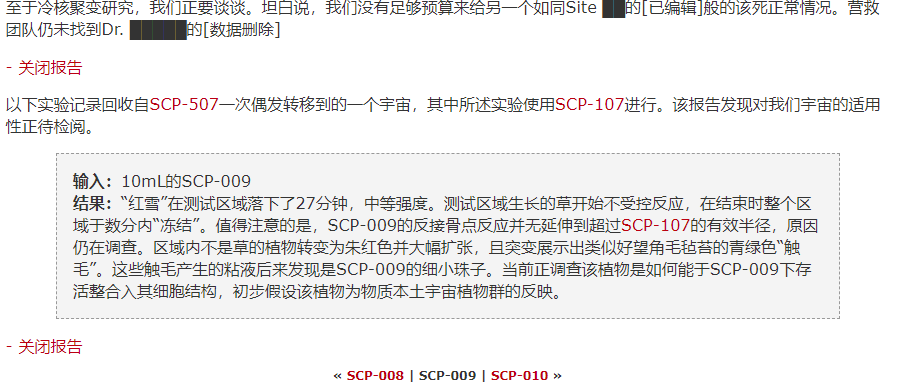
代码如下
import requests
from bs4 import BeautifulSoup
import pdfkit
site = 'http://scp-wiki-cn.wikidot.com/scp-'
def parse_url_to_html(url,name):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
body = soup.find_all(id="main-content")[0]
html = bytes(str(body), encoding = "utf8")
a = name + '.html'
with open(a, 'wb') as f:
f.write(html)
def save_pdf(htmls, name):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, name + '.pdf', options=options)
for i in range(1,10):
n = str(i)
name = n.zfill(3)
url = site + name
parse_url_to_html(url, name)
save_pdf(name+'.html', name)
- 看下这篇博客,也许你就懂了,链接:Python实现抓取HTML网页并以PDF文件形式保存的方法
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^