pandas处理表格数据获得新表格
处理这张表格(图是网上保存的)
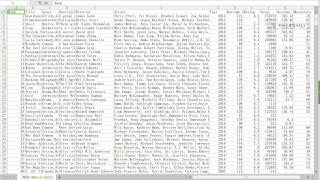
想获得这样一个新表格:
演员甲 参演电影1 参演电影2 参演电影3 …
演员乙 参演电影1 参演电影2 参演电影3 …
演员丙 参演电影1 参演电影2 参演电影3 …
…
请问该怎么写代码,谢谢大佬们的解答!
import pandas as pd
# 创建一个DataFrame作为新表数据
df = pd.DataFrame(data={
'Actors': [],
'Movie1': [],
})
# 读取Excel文件
excel = pd.read_excel('TMDB-Movie-Data.xlsx')
# 遍历Actors列
for index, row in excel['Actors'].iteritems():
actors = row.split(',') # 按“,”拆分Actors
for item in actors:
# 判断当前Actor是否已经在 df 里
if item in df['Actors'].tolist():
row = df.loc[df['Actors'] == item] # 得到当前Actor在df中的行
a = 1
# 判断当前Actor参演的电影记录到了哪一列
try:
while not pd.isnull(df.loc[row.index[0], 'Movie' + str(a)]):
a += 1
except KeyError:
pass
# 在当前Actor所在的行末尾增加一个参演的电影
df.loc[row.index[0], 'Movie' + str(a)] = excel['Title'][index]
else:
# 如果当前的Actor没有记录在df里,则新增
df = df.append({
'Actors': item,
'Movie1': excel['Title'][index]
}, ignore_index=True)
# 将df保存到新表里
df.to_excel('result.xlsx', index=False)
只能是数据行形式吧, 列数可变, 高产演员,可能上百部。