如何将pandas的表导入到特定excel的特定位置
如题,请问如何将pandas生成的表导入到现有excel的特定位置

import pandas as pd
df1 = pd.DataFrame(
{
"num1": [21,25,56,11],
"num2": [31,35,36,12],
"num3": [41,45,46,14],
},
index=[0, 1, 2,3],
)
import pandas as pd
import openpyxl
wb=openpyxl.load_workbook('C:\\Users\\19051\\Desktop\\test1.xlsx')
ws = wb['Sheet1']
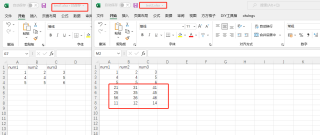
startRow = 5
startCol = 2
for i in range(0, df1.shape[0]):
eachRowList = df1.iloc[i,:].tolist()
for j in range(1,len(eachRowList)+1):
#row 代表从几行开始, columns 代表从第几列开始
#这里是从第5行开始插入
ws.cell(row = i+5, column = j).value =eachRowList[j-1]
wb.save('C:\\Users\\19051\\Desktop\\test2.xlsx')
如果对您有帮助,麻烦采纳,非常感谢~
Pandas能从文本文件和Excel文件中读入数据,形成dataframe,也可以将dataframe导出到文本文件、Excel文件中存储起来。
导入函数有(1)pd.read_csv():导入后缀名为.csv,.txt的文本文件;(2)pd.read_excel():导入后缀名为.xlsx的Excel文件。
导出函数有(1)df.to_csv)():将数据存储到csv文件或txt文件中;(2)df.to_excel():将数据存储到Excel文件中;
无论是导入函数还是导出函数,都有参数 header,表示 dataframe 的列索引。而行索引在导入函数中用参数 index_col 表示,将某列指定为行索引;行索引在导出函数中用参数 index 表示,指示是否要存好行索引。
一、导入文件
(1)导入文本文件:pd.read_csv()
pd.read_csv()函数不仅可以导入csv文件,也可以导入txt文件。
导入test.csv文件
df = pd.read_csv('test.csv')
导入test.txt文件
df = pd.read_csv('test.txt')
指定分隔符
文本文件中,用分隔符来分隔每个值,所以读入的时候,要用参数sep告诉函数分隔符是什么,默认的分隔符是逗号。
指定分隔符是点号 df = pd.read_csv(filename,sep='.')
(2)导入Excel文件:pd.read_excel()
即使在excel中,某列是字符串,但如果它是数值型字符串,导入DataFrame后,仍然会被当成数值,而不是字符串。
导入test.xlsx文件
df = pd.read_excel('test.xlsx')
指定读入excel的sheet页
Excel文件在读入时,默认读取第一页。但如果Excel文件有多页,且不想读取第一页而是其他页,则要用参数sheetname传入读入页的名称。
导入test.xlsx文件的sheet1页
df = pd.read_excel('test.xlsx', sheetname='sheet1')
(3)相对路径和绝对路径
导入文件时,要指定文件所在的路径,可以是相对路径,也可以是绝对路径。
导入windows下的绝对路径:导入E盘下的test.csv
pd.read_csv('E:\test.csv')
导入mac下的绝对路径:导入xxx文件夹下的test.csv
pd.read_csv('/Users/xxx/test.csv')
相对路径指的是当前的py文件所在的路径。当要导入的文件和py文件在同一个文件夹下,则可以用相对路径导入。
pd.read_csv('test.csv')
路径的转义?
Location = r'./test.csv'
df = pd.read_csv(Location)
注意,因为斜线是一个特殊字符,在字符串之前放置前导的 r,将会把整个字符串进行转义。
(4)读取指定的列
有时候,我们并不想把所有的列都读入,只想读取前几列,或后几列,或指定几列。这时,可以使用usecols参数。
读取csv数据中的第0列,第1列,第2列。
df = pd.read_csv('test.csv', usecols=[0,1,2])
(5)行列索引
默认列索引和行索引
导入文件时,若不指定列索引,则默认将文件中的第一行当成dataframe列索引,并且为数据自动添加整数行索引。
默认将test.csv中的第一行当为列索引,自动添加从0开始的整数索引
pd.read_csv('test.csv')
第一行非列索引
若导入时,第一行是数据,并非列标题,可以将参数header设置为None,即不让第一行成为列索引。但系统会自动添加从0开始的列索引。
df = pd.read_csv('test.csv', header=None)
指定某行为列索引
导入数据时默认第一行为列索引,但如果数据中第一行并非标题,而是第k行,则可以用参数header指定第k行为列索引。
指定test.csv中的第3行是列索引
df = pd.read_csv('test.csv', header=3)
添加列索引
若导入的数据中并没有任何一行能当列索引,可以用参数 names 自定义列索引。
指定test.csv(只有两列)中的列索引为['column1','column2']
df = pd.read_csv('test.csv', names=['column1','column2'])
指定行索引
导入数据时,会自动添加从0开始的整数行索引。若需要指定数据中第K列为行索引,则要用index_col参数。
指定第0列是dataframe的行索引
df=pd.read_csv('test.csv',index_col=0)
指定列名为'column'的列是dataframe的行索引
df=pd.read_csv('test.csv',index_col='column')
二、导出数据
(1)写入文本文件:df.to_csv()
pandas可将dataframe存储到csv文件或txt文件中。存储的路径可以是绝对路径,也可以是相对路径。
将数据表df存入当前py文件所在位置下的test.csv文件中,如果没有这个文件,会自动创建
df.to_csv('test.csv')
将数据表df存入当前py文件所在位置下的test.txt文件中,如果没有这个文件,会自动创建
df.to_csv('test.txt')
(2)写入excel文件:df.to_excel()
写入Excel文件时,默认会写入Excel文件中的第一页。
将数据表df写入test.xlsx文件中
df.to_excel('test.xlsx')
如果想要写入指定的页,则用参数sheet_name。
将数据表df写入test.xlsx文件中'Sheet1'页
df.to_excel('test.xlsx',sheet_name='Sheet1')
(3)行列索引
存储行索引
存储时,默认将数据表中的行索引也存储到文件中。
test.csv的行索引将会被存储起来
df.to_csv('test.csv')
不存储行索引
导出数据时,默认是要存储行索引的。不存储行索引的话,设置index的值为False。
df.to_csv('test.csv', index = False)
不存储列索引
导出数据时,默认是要存储列索引的。不存储列索引的话,设置header的值为False。不要列索引,导出的数据就没有列名。
df.to_csv('test.csv', header = False)
需要openpyxl的的协助,楼上已经说得很清楚了
需要openpyxl的的协助,楼上已经说得很清楚了