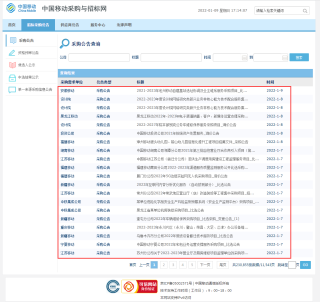
请问怎样用VB.net或C#获取以下网页截图中红框中的标题文字及其链接?
截图网址:
https://b2b.10086.cn/b2b/main/listVendorNotice.html?noticeType=2
需要POST请求:https://b2b.10086.cn/b2b/main/listVendorNoticeResult.html?noticeBean.noticeType=2
参数:page.currentPage=1&page.perPageSize=20¬iceBean.sourceCH=¬iceBean.source=¬iceBean.title=¬iceBean.startDate=¬iceBean.endDate=&_qt=mY3E2NU2N5MmM0UWNygDM4ATY0EDZ2MjM3YjMjZDN3Q
示例代码如下
using System;
using System.Text;
using System.Net;
using System.Text.RegularExpressions;
using System.IO;
namespace ConsoleApp2
{
class Program
{
static void Main(string[] args)
{
var url = "https://b2b.10086.cn/b2b/main/listVendorNoticeResult.html?noticeBean.noticeType=2";
var req = (HttpWebRequest)HttpWebRequest.Create(url);
req.Method = "post";
req.ContentType = "application/x-www-form-urlencoded; charset=UTF-8";
//下面3个头必须
req.Referer = "https://b2b.10086.cn/b2b/main/listVendorNotice.html?noticeType=2";
req.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55";
req.Headers.Add("cookie", "JSESSIONID=B3155698F7F1CF723C2F9E03CB29CDB7");
var s = "page.currentPage=1&page.perPageSize=20¬iceBean.sourceCH=¬iceBean.source=¬iceBean.title=¬iceBean.startDate=¬iceBean.endDate=&_qt=mY3E2NU2N5MmM0UWNygDM4ATY0EDZ2MjM3YjMjZDN3Q";
var data = Encoding.UTF8.GetBytes(s);
req.ContentLength = data.Length;
var io = req.GetRequestStream();
io.Write(data,0,data.Length);
io.Flush();
var resp = (HttpWebResponse)req.GetResponse();
io = resp.GetResponseStream();
var sr = new StreamReader(io);
s = sr.ReadToEnd();
io.Close();
var re = new Regex("selectResult\\('\\d+'\\)\">"
+ "\\s+<td[^>]+>([\\s\\S]+?)</td>"
+ "\\s+<td[^>]+>([\\s\\S]+?)</td>"
+ "\\s+<td[^>]+>([\\s\\S]+?)</td>"
+ "\\s+<td[^>]+>([\\s\\S]+?)</td>\\s*</tr>", RegexOptions.Compiled | RegexOptions.IgnoreCase);
var reTitle = new Regex("title=\"([^\"]+)\"", RegexOptions.Compiled | RegexOptions.IgnoreCase);
var reConent = new Regex("<a[^>]+>([\\s\\S]+?)</a>", RegexOptions.Compiled | RegexOptions.IgnoreCase);
MatchCollection mc = re.Matches(s);
foreach (Match m in mc)
{
string title = m.Groups[3].Value;
title = (title.Contains("title=\"")?reTitle:reConent).Match(title).Groups[1].Value;
Console.WriteLine(m.Groups[1].Value.Trim() + "\t" + m.Groups[2].Value.Trim() + "\t" + title.Trim() + "\t" + m.Groups[4].Value.Trim());
Console.WriteLine();
}
Console.Read();
}
}
}

有其他问题可以继续交流~
首先,把网页HTML抓取回来,然后提取其中的标题和链接,方式有多种: