为什么爬虫爬到了东西但解析不了
import requests
from bs4 import BeautifulSoup
import csv
url='https://www.epo.org/search.html?q=hydrogen%20storage&resultsPerPage=100&sortOrder=1'
data_list=[]
res=requests.get(url)
print(res.status_code)
bs=BeautifulSoup(res.text,'html.parser')
reslist=bs.find_all('a',class_='headlink')
print(reslist)
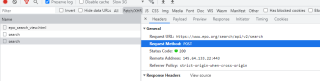
最后一行出来的结果是'[]'
为什么啊
网址数据是动态加载的,requests无法获取,需要找到数据接口来请求。数据接口网址:https://www.epo.org/search/api/v2/search
需要post请求,发送参数
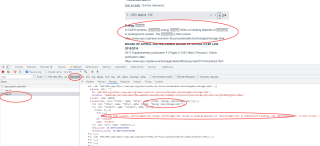

你写的代码问题挺多的 我扫了一眼就看到了两处错误
1.url里不能带parma数据
2.%20 需转义
要爬什么网站
要爬什么内容
我把示范给你看