1月10日更,刚接触爬虫,遇到了一些困难
个人不是计算机专业,因为兴趣学了一段时间的网络爬虫,所以写的代码可能比较粗糙,还请老师们多多指教。
这次想拿马云的微博进行爬虫试试手,可是发现微博的下滑是懒加载的,而且下滑一段距离他的刷新也是随机的
因为昨天在爬虫时候,每次爬回来的数据只有一小部分而已,而且只是当前视图的内容。就推测他随着下滑刷新,新内容会代替掉就内容,旧内容就没办法没爬到。
现在请教一下各位老师们,代码应该怎么改才好
————————————————————————————
2022年1月10日
现在代码改用通过接口模拟请求的方式

可是不知道要怎么解析,接口我打开过是这样
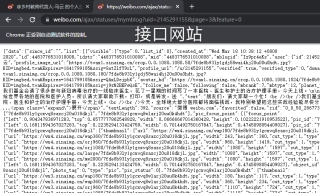
用了json解析不了,不知道哪里错了,beautifulsoup解析出来是乱码
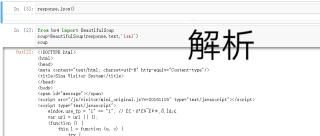
selenium是可以通过运行js语句下滑页面的,
例如
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://blog.csdn.net/maybe_frank/article/details/79374866')
i=100
for i in range(2,90): #也可以设置一个较大的数,一下到底
js = "var q=document.documentElement.scrollTop={}".format(i*100) #javascript语句
driver.execute_script(js)
1、可以通过network查看动态网页fetch和xhr出现数据的url进行爬取
2、通过selenium模拟访问实现爬取,这种方法较为安全
下滑加载的应该是ajax,也就是通过接口返回json协议的数据,然后通过js写入页面,你直接找到接口请求模拟网络协议请求就好