scrapy框架爬取结构设计问题
是搭建爬取当当图书的爬虫,
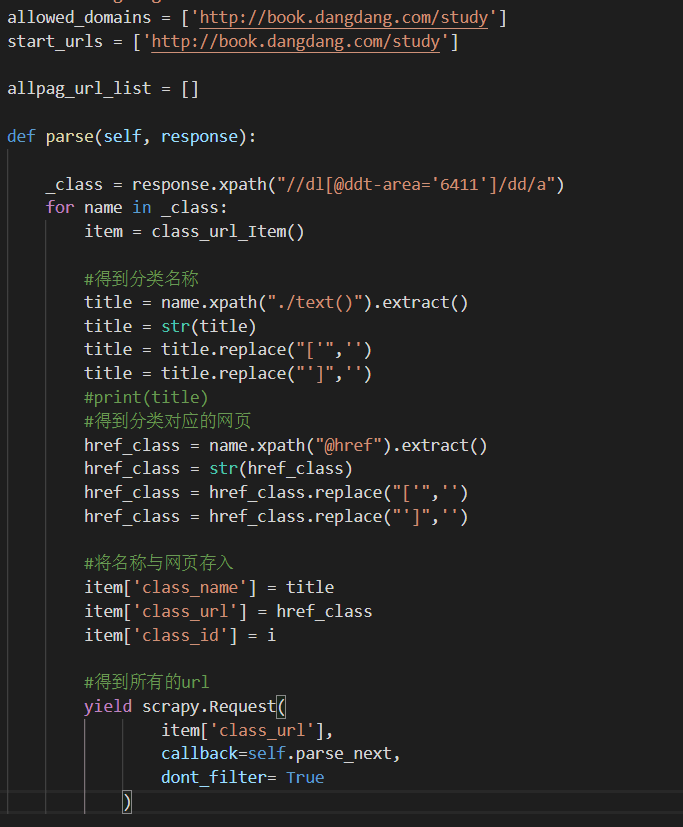
在第一个paser是为了得到所有的分类,比如一年级,二年级等等
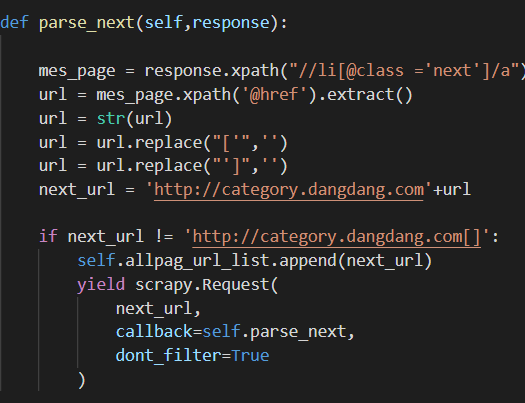
第二个paser_next 是为了得到所有页的url
但是我在下一步对每一页的url进行解析时,不知道该字母搭建一个入口
如果放在第一个paser里面,allpag_url_list是空表
如果放在第二个paser_next 里面,则会重复解析
我的想法是能否想办法让paser中执行到yield时停止,直到paser_next解析完毕之后 继续执行语句
但是我并不知道该怎么办才能实现
希望各位指教
附两张图
- 这篇文章:Scrapy模拟登陆豆瓣抓取数据 也许能够解决你的问题,你可以看下
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^