python爬虫 SVG映射反爬虫绕过需求
问题相关代码
import requests
import re
from lxml import etree
from parsel import Selector
# 获取svg css文件
url = 'http://www.porters.vip/confusion/food.html'
svg_url = 'http://www.porters.vip/confusion/font/food.svg'
css_url = 'http://www.porters.vip/confusion/css/food.css'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
svg_text = requests.get(svg_url).text
css_text = requests.get(css_url).text
# print(svg_text)
# print(css_text)
# 清除转行和空格,方便匹配
css_text = css_text.replace('\n','').replace(' ','')
# css坐标提取
css_class_name = 'vhkbvu'
pattern = re.compile('.%s{background:-(\d+)px-(\d+)px;}'%css_class_name)
coord = pattern.findall(css_text)
print(coord)
if coord:
x_ = coord[0][0]
y_ = coord[0][1]
x = int(x_)
y = int(y_)
print(x,y)
find_xy = ((x),(y))
# svg解析
text = re.findall('y="(.*?)">(.*?)</text>',svg_text,re.S)
list_y = []
list_text = []
for i in range(len(text)):
list_y.append(text[i][0])
list_text.append(text[i][1])
print(list_y)
print(list_text)
# 寻找svg文件中定义的字符大小
find_font_size = re.compile(r'font-size:(\d+)px')
size = find_font_size.findall(svg_text)
print(size)
soup = Selector(svg_text).xpath('//text')
print(soup)
list_y = [i.get('y_') for i in soup]
list_text = [i.text for i in soup]
svg_font_size = find_font_size.findall(svg_text)
find_xy = ((x),(y))
real_y = [i for i in text if y <= i][-1]
real_text = list_text[list_y.index(real_y)]
print(real_text)
Traceback (most recent call last):
list_y = [i.get('y_') for i in soup]
TypeError: get() takes 1 positional argument but 2 were given
我想要达到的结果
需求:
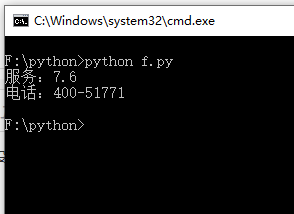
通过映射的方式来获取其中的服务评分以及电话号码,并能够进行完整的结果打印即可
题主要的代码如下
import re
import requests
from parsel import Selector
from lxml import etree
def getCssNumber(css_class_name):
n=kvCls2Number.get(css_class_name,-1)
if n!=-1:
return n
pile = '.%s{background:-(\d+)px-(\d+)px;}'%css_class_name
pattern = re.compile(pile) # 先编译
coord = pattern.findall(css)
x,y = coord[0]
x,y = int(x),int(y)
# 根据y值来确定,css的位置 --》 svg对应的值,取最近的一个值
axiy = [i.attrib.get('y') for i in texts if y<=int(i.attrib.get('y'))][0]
# 提取对应的y的text
svg_text_ = svg_data.xpath("//text[@y=%s]/text()"%axiy).extract_first()
# 提取字体大小
fout_size = re.search('font-size:(\d+)px;',svg_text).group(1)
# css对应的坐标/字体大小=svg坐标
position = x//int(fout_size)
number = svg_text_[position]
kvCls2Number[css_class_name]=number
return number
url = 'http://www.porters.vip/confusion/food.html'
svg_url = 'http://www.porters.vip/confusion/font/food.svg'
css_url = 'http://www.porters.vip/confusion/css/food.css'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Host': 'www.porters.vip'
}
svg_text = requests.get(svg_url).text
css_text = requests.get(css_url).text
css = css_text.replace('\n','').replace(' ','')
svg_data = Selector(svg_text)
texts = svg_data.xpath("//text")
kvCls2Number={}#用来存储已经获取到的样式对应的数字,不需要每次重复获取
res = requests.get(url,headers=headers)
tree=etree.HTML(res.text)
detail=tree.xpath('//div[@class="col details"]')[0]
span=detail.xpath('.//span[@class="comment_score"]/span')[-1]
serviceNumber=(getCssNumber(span.xpath('.//d/@class')[0]))
serviceNumber+=span.xpath('text()')[-1]
print('服务:'+serviceNumber)
phoneCls=detail.xpath('.//div[@class="col more"]/d/@class')
phone=""
for c in phoneCls:
if c=="":
phone+="-"
else:
phone+=getCssNumber(c)
print('电话:'+phone)

有帮助或启发麻烦点下【采纳该答案】,谢谢~~有其他问题可以继续交流~
获取的Selector对象要解析一下,并且用正则表达式析出数据。参考如下代码:
soup = Selector(svg_text).xpath('//text').extract()
print(soup)
list_y = [re.findall('y=\"(\d+)\"',x) for x in soup]
list_text = [re.findall('<text> (.*?)</text>',x) for x in soup]
svg_font_size = find_font_size.findall(svg_text)
find_xy = ((x),(y))
print(find_xy)
real_y = [i for i in text if y <= int(i[-1])]
print(real_y)