添加数据到csv文件?
请帮忙解答下
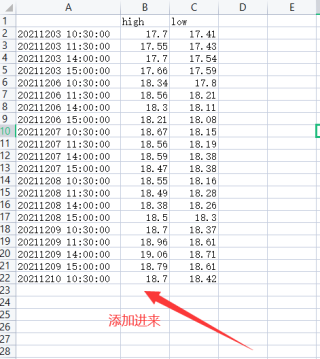
a=['20211206 10:30:00', '20211206 11:30:00', '20211206 14:00:00']
b=[[18.34, 17.8], [18.56, 18.21], [18.3, 18.11]]
#1.想要得到 c=[['20211206 10:30:00',18.34, 17.8],['20211206 11:30:00',18.56, 18.21],['20211206 14:00:00',18.3, 18.11]]
#2.得到的c 添加到本地已有的csv文件000001.SZ.csv中的已有数据的后面(使用这个嘛?to_csv)
#3.df2.to_csv(f'C:/Users/pv/Desktop/测试数据/000001.SZ.csv') c盘前面的 f 是什么意思
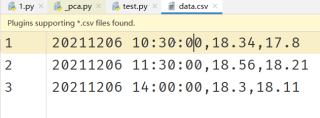
import csv
a=['20211206 10:30:00', '20211206 11:30:00', '20211206 14:00:00']
b=[[18.34, 17.8], [18.56, 18.21], [18.3, 18.11]]
with open('data.csv', 'w', newline='') as file :
writer = csv.writer(file)
for i in range(len(a)) :
writer.writerow([a[i], b[i][0], b[i][1]])
a=['20211206 10:30:00', '20211206 11:30:00', '20211206 14:00:00']
b=[[18.34, 17.8], [18.56, 18.21], [18.3, 18.11]]
c = [[x]+y for x,y in zip(a,b)]
print(c)
f''是格式化字符串,比如f'xxx{a}'是把字符串中{a}替换成a变量的值
如
a=123
print(f'xxx{a}') 输出xxx123
import csv
with open(filename, mode = 'a+', encoding = 'utf-8', newline = '') as f:
wri = csv.writer(f)
a = ['20211206 10:30:00', '20211206 11:30:00', '20211206 14:00:00']
b = [[18.34, 17.8], [18.56, 18.21], [18.3, 18.11]]
for i, v in enumerate(a):
res = [v] + list(map(str, b[i]))
wri.writerow(res)
f是字符串的格式化,称f-string格式化,相当于格式化中的% 或format