svm识别手写数字优化
代码在jupyter上跑的非常慢,并且输出的测试准确率很低,要怎么优化代码呢?
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
def getdata(_dir):
images= []
labels = []
for cls in os.listdir(_dir):
cls_dir = os.path.join(_dir,cls)
for file in os.listdir(cls_dir ):
img = cv2.imread(os.path.join(cls_dir,file ),-1)
images.append(img)
labels.append(int(cls))
return np.array(images),np.array(labels)
_dir_train=r"C:\Users\lenovo\Desktop\python\mnist_train"
_dir_test=r"C:\Users\lenovo\Desktop\python\mnist_test"
Xtrain,Ytrain = getdata(_dir_train)
Xtest,Ytest= getdata(_dir_test)
images_and_labels=list(zip(Xtrain,Ytrain))
plt.figure(figsize=(8, 6))
for index, (image, label) in enumerate(images_and_labels[:8]):
plt.subplot(2, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: %i' % label, fontsize=20);
from sklearn import svm
clf = svm.SVC(gamma='auto', C=1.0, probability=True,max_iter=5000)
h=Xtrain.shape[1]
w=Xtrain.shape[2]
print(Ytrain.shape)
Xtrain=Xtrain.reshape(-1,784)
Xtest=Xtest.reshape(-1,784)
clf.fit(Xtrain, Ytrain);
print("train finished!")
from sklearn.metrics import accuracy_score
Ypred = clf.predict(Xtest);
ret = accuracy_score(Ytest, Ypred)
print(ret)
换一个模型就可以了
clf = svm.LinearSVC(max_iter=10000)
慢的主要原因是模型保存那一步导致的。
测试集准确率不低呀。
之前有人问过,特地整合了项目,可以看看。
https://github.com/linnnff/SVM-Handwritten-mathematical-recognition
你好,请参考我的代码:
# -*- coding: utf-8 -*-
#导入自带数据集
from sklearn import datasets
#导入交叉验证库
from sklearn import model_selection
#导入SVM分类算法库
from sklearn import svm
#导入图表库
import matplotlib.pyplot as plt
#生成预测结果准确率的混淆矩阵
from sklearn import metrics
#读取自带数据集并赋值给digits
digits = datasets.load_digits()
#将数据集中的目标赋给Y
Y=digits.target
#使用reshape函数对矩阵进行转换,并赋值给X
n_samples = len(digits.images)
X = digits.images.reshape((n_samples, 64))
#随机抽取生成训练集和测试集,其中训练集的比例为60%,测试集40%
X_train, X_test, y_train, y_test = model_selection .train_test_split(X, Y, test_size=0.4, random_state=0)
#生成SVM分类模型
clf = svm.SVC(gamma=0.001)
#使用训练集对svm分类模型进行训练
clf.fit(X_train, y_train)
#使用测试集衡量分类模型准确率
res=clf.score(X_test, y_test)
print(res)
#对测试集数据进行预测
predicted=clf.predict(X_test)
expected=y_test
#生成准确率的混淆矩阵(Confusion matrix)
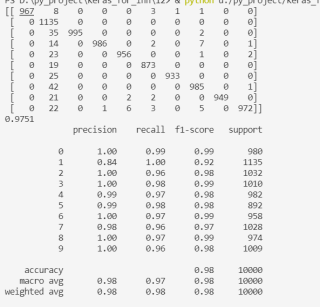
confusion_matrix=metrics.confusion_matrix(expected, predicted)
print(confusion_matrix)
运行结果:
0.9930458970792768
[[60 0 0 0 0 0 0 0 0 0]
[ 0 73 0 0 0 0 0 0 0 0]
[ 0 1 69 0 0 0 0 1 0 0]
[ 0 0 0 70 0 0 0 0 0 0]
[ 0 0 0 0 63 0 0 0 0 0]
[ 0 0 0 0 0 87 1 0 0 1]
[ 0 0 0 0 0 0 76 0 0 0]
[ 0 0 0 0 0 0 0 65 0 0]
[ 0 1 0 0 0 0 0 0 77 0]
[ 0 0 0 0 0 0 0 0 0 74]]
准确率99.3%
如有帮助,请点击我评论上方【采纳该答案】按钮支持一下。
从混淆矩阵中可以看到,大部分的数字SVM的分类和预测都是正确的,但也有个别的数字分类错误,例如真实的数字2,SVM模型有一次错误的分类为1,还有一次错误分类为7。
如有帮助,请点击我评论上方【采纳该答案】按钮支持一下。