为什么我的手写数字识别机器学习的准确率在迭代30次之后就会开始下降呢?
问题遇到的现象和发生背景
机器学习的手写数字识别,用了mnist数据集,可是在迭代30轮之后训练和测试的准确都会开始下降这是为什么呢?
问题相关代码,请勿粘贴截图
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from keras.utils import np_utils
import matplotlib .pyplot as plt
from pylab import mpl
def splitdata(datalist):
inputs_list = []
targets_list = []
for record in datalist:
all_values=record.split(',')
inputs=np.asfarray(all_values[1:])/255
targets=np.zeros(10)
targets[int(all_values[0])]=1
inputs_list.append(inputs)
targets_list.append(targets)
return np.array(inputs_list), np.array(targets_list)
train_data_file=open('E:\mnist_dataset_csv\mnist_train.csv','r')
train_data_list=train_data_file.readlines()
train_data_file.close()
train_inputs,train_targets = splitdata(train_data_list)
test_data_file = open('E:\mnist_dataset_csv\mnist_test.csv','r')
test_data_list = test_data_file.readlines()
test_data_file.close()
test_inputs,test_targets = splitdata(test_data_list)
def create_model(num_inputs,hidden_nodes,num_classes):
model = Sequential()
model.add(Dense(units=hidden_nodes, input_dim=num_inputs,kernel_initializer='normal',activation='sigmoid'))
model.add(Dense(units=num_classes,kernel_initializer='normal',activation='sigmoid'))
model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1), metrics=['accuracy'])
return model
def score(nn, inputs, targets):
scorecord = []
outputs = nn.predict(inputs)
for i in range(outputs.shape[0]):
correct_label = np.argmax(targets[i])
label = np.argmax(outputs[i])
if(label == correct_label):
scorecord.append(1)
else:
scorecord.append(0)
scorecord_array = np.asarray(scorecord)
return scorecord_array.sum() / scorecord_array.size
model = create_model(train_inputs.shape[1],50,train_targets.shape[1])
train_scores=[]
test_scores=[]
for e in range(50):
print('第%d次迭代...'%(e+1))
model.fit(x=train_inputs,y=train_targets,epochs=1,batch_size=1)
train_scores.append(score(model,train_inputs,train_targets))
test_scores.append(score(model,test_inputs,test_targets))
print('训练准确率:%f'%train_scores[e])
print('测试准确率:%f'%test_scores[e])
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,4))
plt.xlabel('迭代轮数')
plt.ylabel('准确率')
plt.plot(range(1,51),train_scores,c='red',label='训练准确率')
plt.plot(range(1,51),test_scores,c='blue',label='测试准确率')
plt.legend(loc='best')
plt.grid(True)
plt.show()
运行结果及报错内容
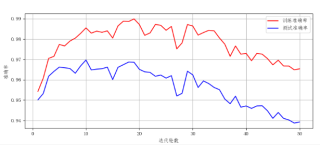
我的解答思路和尝试过的方法
我想要达到的结果
当你的参数数量太少,或者参数精度过低,那么你就不可能期待最终学习的效果有多好。
不管你参数再多,再精确,它总会有个上限,永远到不了100%
当你学习次数到了一定程度,成果已经达到了所能达到的最好,继续学习只能让你的参数偏离最优解
类似过拟合吗?可以去搜一下过拟合怎么解决,我自己一般是(用python提供的 matplotlibt 库)画损失函数和精准读图像,然后截取效果最好一次的数据