sql查询问题对于某一字段连续且重复,只取一
sql查询结果中,对于某一字段连续重复时,只取第一条(或最后一条),例如:
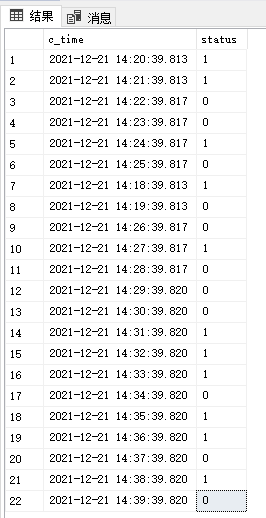
以上结果集中,我想让他变成
c_time status
2021-12-21 14:20:39.813 1
2021-12-21 14:22:39.817 0
2021-12-21 14:24:39.817 1
。
。
根据status字段,把结果里相连的,重复的行数只取其中一行,要怎么写查询语句?
这里要使用开窗函数进行分组排序
select c_time,status from
(select row_number() over(partition by status order by c_time) rn,c_time,status from 表 ) as t
where rn=1
里面的 order by c_time,加ASC或者DESC可以决定是取第一条还是最后一条
根据题主补充描述,应该使用以下sql
create table table1 (index1 int, status1 int);
insert into table1 values (0, 0);
insert into table1 values (1, 0);
insert into table1 values (2, 0);
insert into table1 values (3, 0);
insert into table1 values (4, 1);
insert into table1 values (5, 1);
insert into table1 values (6, 0);
insert into table1 values (7, 0);
insert into table1 values (8, 0);
insert into table1 values (9, 0);
insert into table1 values (10, 1);
insert into table1 values (11, 1);
insert into table1 values (12, 1);
insert into table1 values (13, 1);
insert into table1 values (14, 1);
insert into table1 values (15, 0);
insert into table1 values (16, 0);
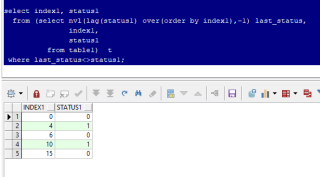
select index1, status1
from (select nvl(lag(status1) over(order by index1),-1) last_status,
index1,
status1
from table1)
where last_status<>status1;
实测和题主要求一致
以上是在oracle数据库中进行的测试,如果是在其他数据库,nvl空值处理的函数可能要换成对应数据库中的函数
select distinct c_time form 表名
with t as (
select CONVERT(datetime,'2021-12-21 14:20') c_time,1 status
union all select '2021-12-21 14:21',1
union all select '2021-12-21 14:22',0
union all select '2021-12-21 14:23',0
union all select '2021-12-21 14:24',1
union all select '2021-12-21 14:25',0
union all select '2021-12-21 14:26',1
union all select '2021-12-21 14:27',0
union all select '2021-12-21 14:28',0
union all select '2021-12-21 14:29',0
union all select '2021-12-21 14:30',1
),t1 as (
select *,ROW_NUMBER() over(order by @@rowcount) as rid from t
)
select * from t1 a where not exists(select 1 from t1 where rid=a.rid-1 and status=a.status)

select c_time,status
from 表名
group by c_time,status
重新说一下把,例如表tabel中有字段index和字段status,有以下示例数据:
index status
0 0
1 0
2 0
3 0
4 1
5 1
6 0
7 0
8 0
9 0
10 1
11 1
12 1
13 1
14 1
15 0
16 0
那么我希望查询后的结果为:
index status
0 0
4 1
6 0
10 1
15 0