python用requests和bs4库写爬虫,如下问题该如何解决

我想将图片中蓝底这几行中的“美国”找出来,代码该如何写。我的代码如下所示,但是执行后返回的是None
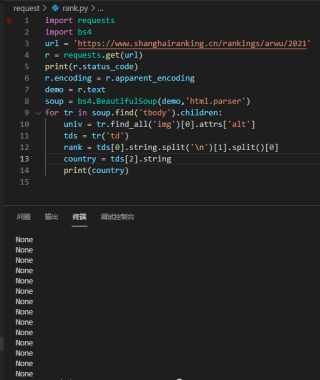
bs解析起来不方便,而且元素容易找错,建议用xpath配合re使用。
代码仅供参考:
import requests
import re
from lxml import etree
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url='https://shanghairanking.cn/rankings/arwu/2021'
res=requests.get(url,headers=headers)
res.encoding=res.apparent_encoding
dom=etree.HTML(res.text)
school_name=re.findall('<img alt="(.*?)"',res.text)
school_local=dom.xpath("//tbody/tr/td[3]/text()")
school_rank=dom.xpath('//tbody/tr/td[4]/text()')
for i in range(len(school_name)):
print(
'学校名称:',school_name[i],
'国家/地区:',school_local[i].strip().replace('\n',''),
'国家/地区排名',school_rank[i].strip().replace('\n','')
)