使用pdfplumber出现cid
问题遇到的现象和发生背景
用pdfplumber读取pdf文件,出现cid,观察一看pdf中这一部分是公式
问题相关代码,请勿粘贴截图
import pdfplumber
# 读取pdf并选择对应的页数
pdf = pdfplumber.open('30.pdf')
page = pdf.pages[0]
# 提取文本并可视化
words = page.extract_text(x_tolerance=1)
print(words)
# tables=page.extract_table()
# print(tables)
运行结果及报错内容
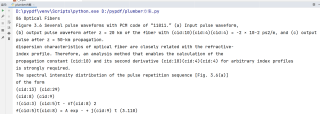
文件内容是

我的解答思路和尝试过的方法
根据cid后面的数字还原公式
我想要达到的结果
还原pdf内容就行了,知道cid每个对应的是什么也行
这个公式是图片,pdfplumber处理不了图片