python中怎么统计单词个数和提取每个单词中的首字符?
图中就是 number_of_words(ls):
要统计 fist_letter(ls) 要提取首字母完整程序
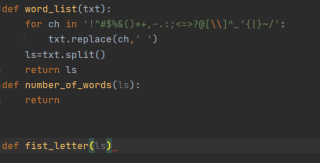
然后完整的代码是这个:
```python
import re
import string
def read_file(file): #打开本地的一个txt文件 里面是一篇英语文章
""" """
with open(file,'r',encoding='utf-8') as f:
text =f.read()
return text
def classify_char(txt): #这里是统计大写、小写、数字、空格和其他字符
upper=0
lower=0
digit=0
space=0
other=0
for ch in txt:
if ch.isupper():
upper = upper+1
elif ch.islower():
lower = lower + 1
elif ch.isdigit():
digit=digit+1
elif ch.isspace():
space=space+1
else:
other=other+1
return upper,lower,digit,space,other
def word_list(txt): #这里将字符中的符号代替空格
for ch in '!"#$%&()*+,-.:;<=>?@[\\]^_‘{|}~/':
txt.replace(ch,' ')
ls=txt.split()
return ls
def number_of_words(ls): #这里是统计字符单词数量
def first_letter(ls): #这里是要提取字符的首字符
if __name__ == '__main__': #输出
filename='essay1_The Language of Music.txt'
text=read_file(filename)
classify= classify_char(text)
word_conuts = number_of_words(word_list)
print('大写字母{}个,小写字母{}个,空格{}个,其他{}个'.format(*classify))
print(f'共有{word_conuts}单词')
new_str=first_letter(word_list())
print(len(new_str))
print(f'拼接的字符串是{new_str}')
```
用正则表达式[a-zA-Z]+ 统计单词个数
你题目的解答代码如下:
import re
import string
def read_file(file): #打开本地的一个txt文件 里面是一篇英语文章
""" """
with open(file,'r',encoding='utf-8') as f:
text =f.read()
return text
def classify_char(txt): #这里是统计大写、小写、数字、空格和其他字符
upper=0
lower=0
digit=0
space=0
other=0
for ch in txt:
if ch.isupper():
upper = upper+1
elif ch.islower():
lower = lower + 1
elif ch.isdigit():
digit=digit+1
elif ch.isspace():
space=space+1
else:
other=other+1
return upper,lower,digit,space,other
def word_list(txt): #这里将字符中的符号代替空格
ls=re.findall(r'[a-zA-Z]+',txt)
return ls
def number_of_words(ls): #这里是统计字符单词数量
return len(ls)
def first_letter(ls): #这里是要提取字符的首字符
return [x[0] for x in ls]
if __name__ == '__main__': #输出
filename='essay1_The Language of Music.txt'
text=read_file(filename)
classify= classify_char(text)
word_conuts = number_of_words(word_list(text))
print('大写字母{}个,小写字母{}个,空格{}个,其他{}个'.format(*classify))
print(f'共有{word_conuts}单词')
new_str=first_letter(word_list(text))
print(len(new_str))
print(f'拼接的字符串是{new_str}')
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!
