tacotron(seq2seq)模型训练80k步后损失函数上升
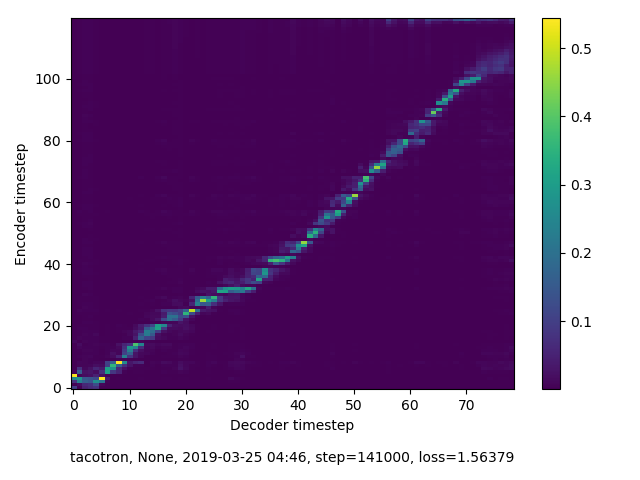
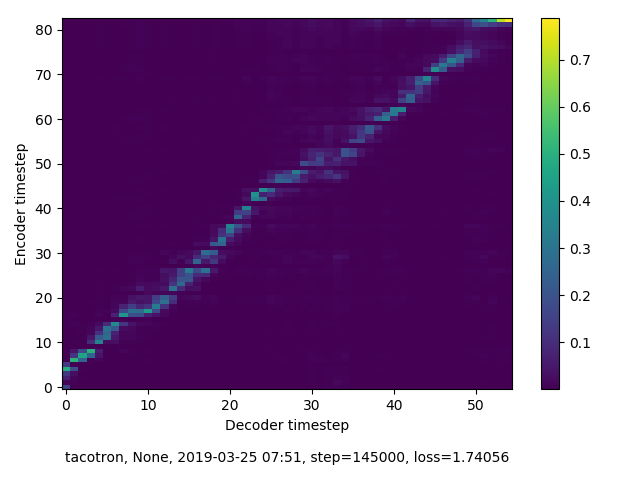
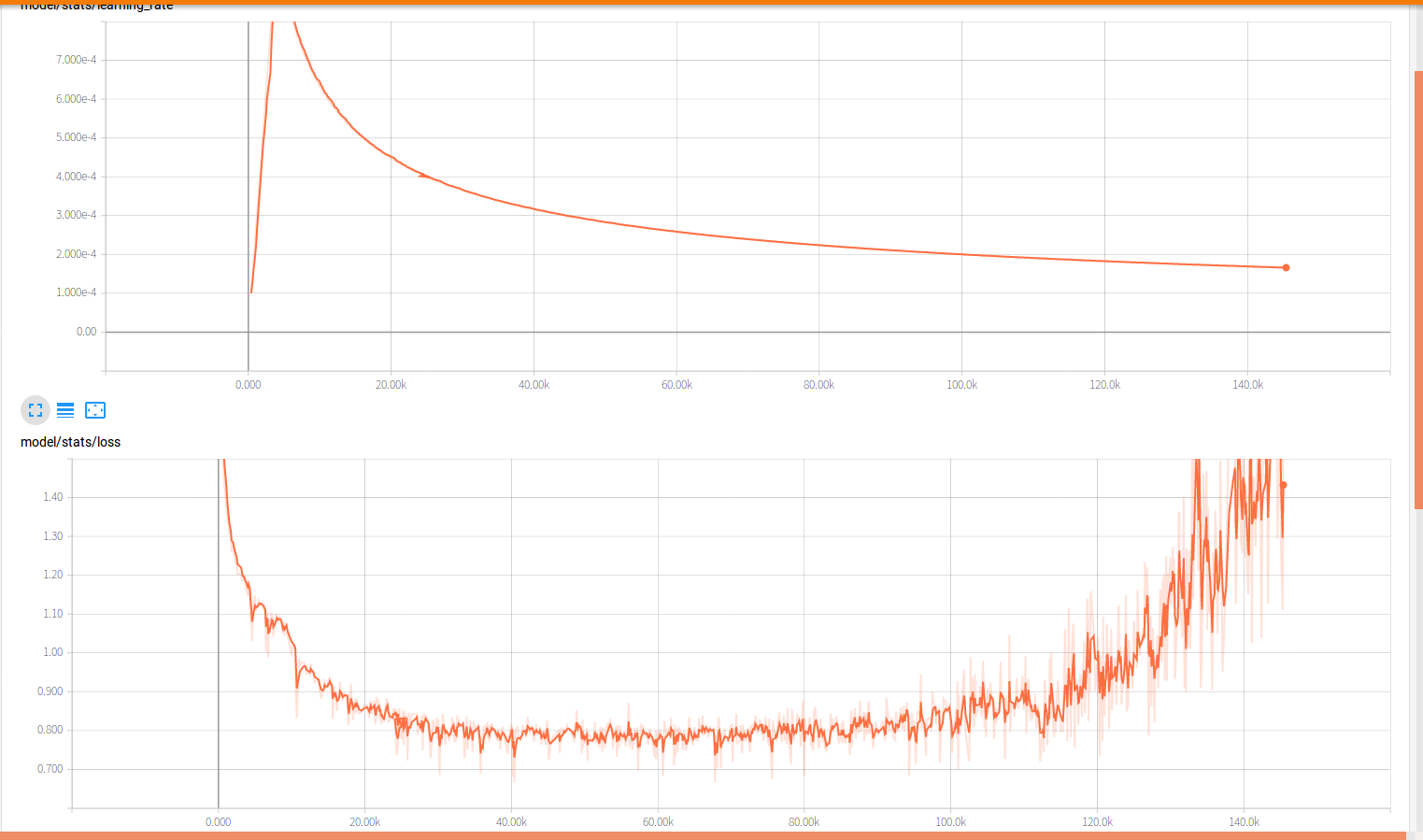
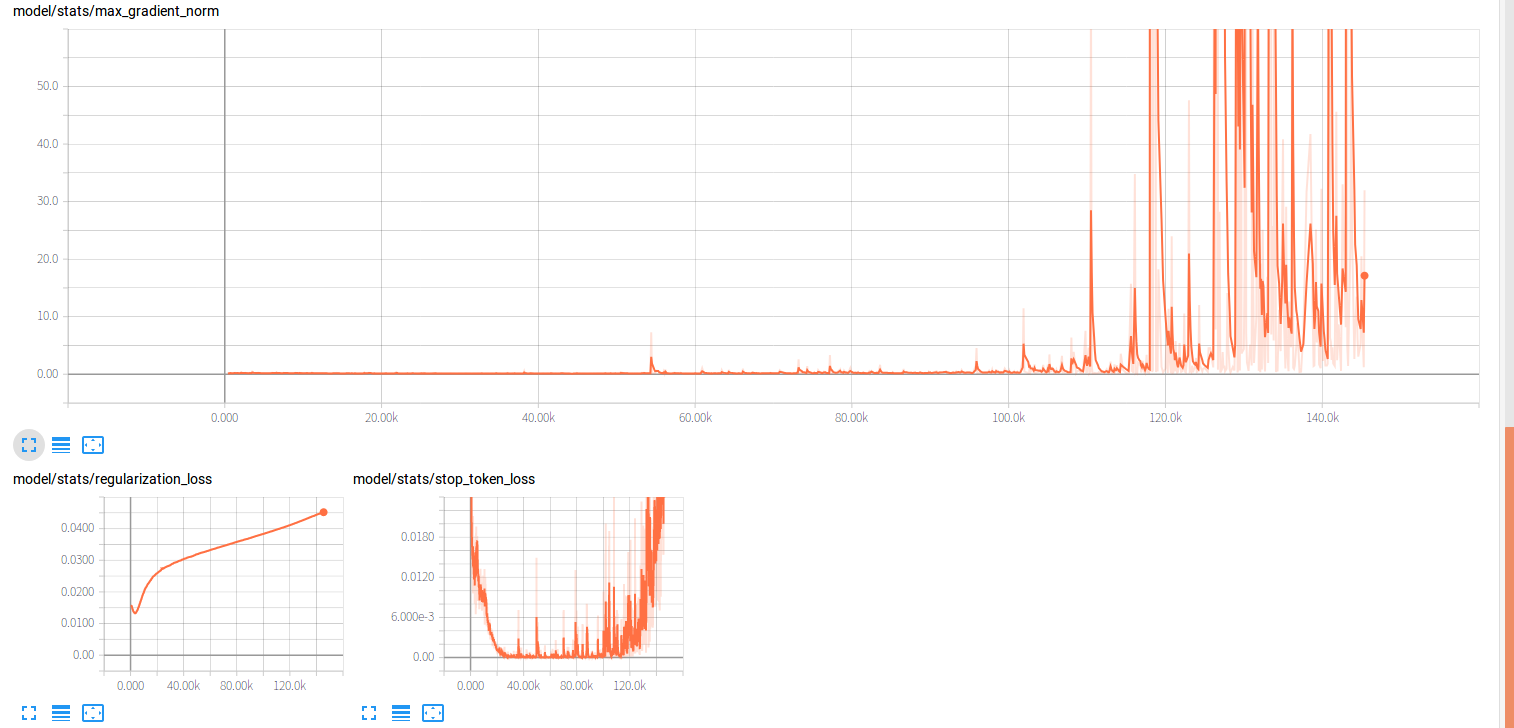
用10h的中文数据集训练Google tacotron(seq-attention-seq)模型,每次训练到80k步后损失就开始猛涨(梯度爆炸?)而且loss最低值下降到了0.75左右。但是模型的alignment很明显,合成语音只是有杂声。怎么解决?
alignment:
学习率/损失/梯度等曲线:
** 模型参数:**
# 模型:Tacotron 1
outputs_per_step=5,
embed_depth=512,
prenet_depths=[256, 256],
encoder_depth=256,
postnet_depth=512,
attention_depth=128,
decoder_depth=1024,
# 优化器:Adam
batch_size=32,
adam_beta1=0.9,
adam_beta2=0.999,
initial_learning_rate=0.002,
decay_learning_rate=True,
use_cmudict=False,
# Initializer:
truncated_normal_initializer
# 学习率延迟:
step = init_lr * warmup_steps**0.5 * tf.minimum(step * warmup_steps**-1.5, step**-0.5)
学习率降低一些,用dropout/正则化防止过拟合,还有增加训练数据量或者提前结束训练。