<python>python爬取智联json页面,但是爬回来的数据不全?
1.智联一页有大概100条数据,但是爬回来只有20条
代码: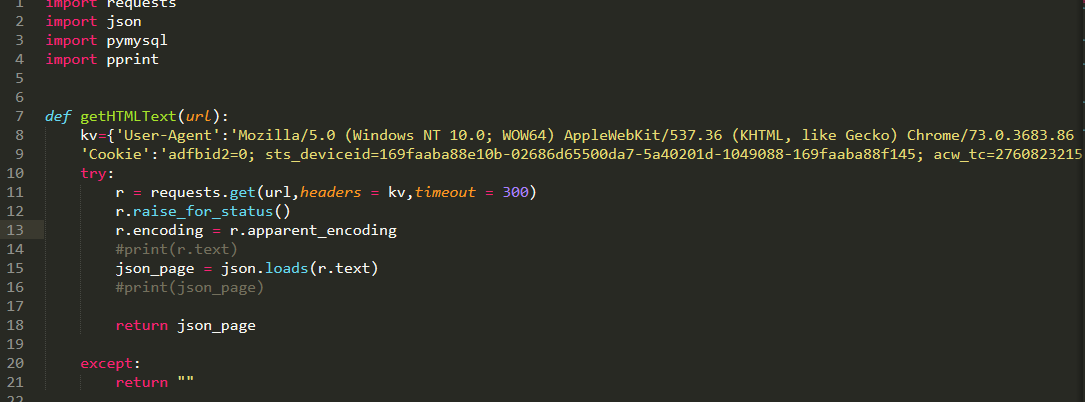
https://img-ask.csdn.net/upload/201905/07/1557194839_124865.png
主函数: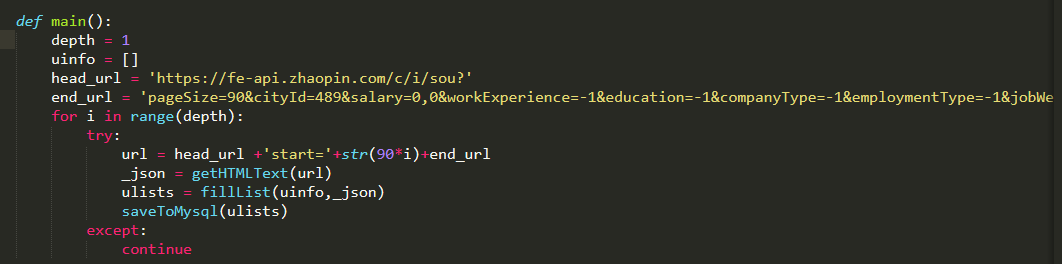
depth是爬取的页数,1页的时候只能在数据库看到20条记录,当把depth改成10的时候可以看到1000条信息,但是之后depth再增加(如改成20,30等)数据也不会再增加了,一直是1000条信息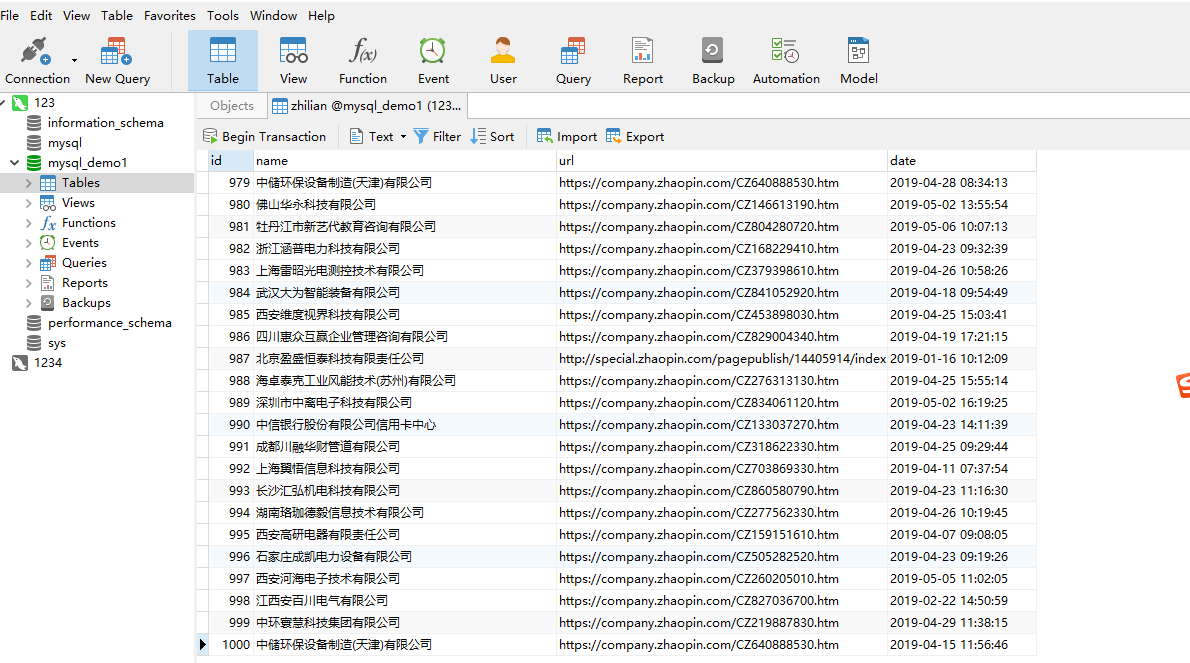
我觉得不是存储的问题,因为第一个爬取的函数返回来的页面就已经少了,只有20条,麻烦帮忙看一下这个爬取函数有什么问题,谢谢啦
看下智联是不是采用ajax的方式滚屏异步加载的,这个你可以用浏览器访问,然后f12抓包分析下。
现在很多反爬机制
1 文字用特殊字体编码,http请求饭返回的是乱码
2 屏蔽频繁请求,直接返回固定页或者乱码页
3 ajax 动态加载,你需要使用 selenium 之类的