用爬虫爬区世界大学排名一直报错且无法爬取完整信息
我应该怎么改?
代码如下
import csv
import os
import requests
from bs4 import BeautifulSoup
allUniv = []
csvUniv = []
ranking = 11
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'gb2312'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
def writercsv(book,num,table):
if os.path.isfile(book):
with open(book,'a',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
for i in range(num):
u=csvUniv[i]
csv_write.writerow(u)
else:
with open(book,'w',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
for i in range(num):
u=csvUniv[i]
csv_write.writerow(u)
def printUnivList(num):
for i in range(num):
u=allUniv[i]
print("{1:^15}\t{2:{0}^11}\t{3:^54}\t{4:^5}\t{5:^20}\t".format(chr(12288),u[0],u[1],u[2],u[3],u[4]))
table=["排名","学校中文名称","学校英文名称","国家/地区""得分"]
def main():
url = 'https://www.igo.cn/zt/University_Rankings/?utm_source=source-baidu&tm_medium=xtjy22&utm_term=JS-TY-%E6%8E%92%E5%90%8D&utm_content=QS&tm_campaign=2021%E5%B9%B4%E5%BA%A6QS%E4%B8%96%E7%95%8C%E5%A4%A7%E5%AD%A6%E6%8E%92%E5%90%8D&bd_vid=7602746426293878947'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(soup)
printUnivList(ranking)
writercsv(book,ranking,table)
main()
报错是下面这个:
csv_write.writerow(u)
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 30: illegal multibyte sequence
报什么错误。你把代码发完整
把你的代码用代码段</>的文本形式发完整,我调试下看看
另外,你是用 requests 和 BeautifulSoup爬取网页的吗?
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
对于动态更新的内容要用selenium 来爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
在页面上点击右键,右键菜单中选 "查看网页源代码"。
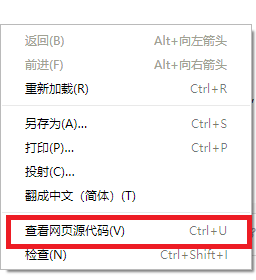
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,要用selenium 来爬取.
对答案满意的话。麻烦给采纳一下!谢谢!