在网络爬取百度图片时遇到的问题
问题遇到的现象和发生背景

问题相关代码,请勿粘贴截图
import os, re, requests
root = 'E:/PycharmProjects/pythonProhttps://img-mid.csdnimg.cn/release/static/image/mid/ask/862977902936192.png "#left")
ject/百度图片'
if not os.path.exists(root):
os.makedirs(root)
pattern = r'"ObjURL":"(.*?)"'
pattern = re.compile(pattern)
def getTextFromHtml(url):
cReturn = ""
try:
r = requests.get(url, timeout=30, headers={'Accept': 'application/json, text/javascript, */*; q=0.01','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Connection':'keep-alive','Sec-Fetch-Dest': 'empty','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.11261 SLBChan/103'})
r.raise_for_status()
r.encoding = r.apparent_encoding
cReturn = r.text
except:
cReturn = ''
return cReturn
def download(List):
for u in List:
try:
path=root+u.split('/')[-1]
u = u.replace('\\', '')
r = requests.get(u, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(r.content)
f.close()
print(path + ' 文件保存成功')
except:
print(u, "下载失败,可能链接不是指定格式图片")
def getOtherPage(nPage, nNum, word):
urllist = []
url = r'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word={word}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn={pn}&rn={rn}'
for x in range(1, nPage + 1):
u = url.format(word=word, pn=nNum * x, rn=nNum)
urllist.append(u)
return urllist
n = 30
page = int(input('输入想下载多少页图片(每页%d张图片):' % (n)))
word = input('输入想下载的图片搜索关键字:')
url = 'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1499773676062_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word={word}'.format(word=word)
html = getTextFromHtml(url)
firstUrlList = re.findall(pattern, html)
download(firstUrlList)
otherUrlList = getOtherPage(page, n, word)
for i in range(page):
html = getTextFromHtml(otherUrlList[i])
url = re.findall(pattern, html)
download(url)
运行结果及报错内容

我的解答思路和尝试过的方法
该代码能够运行,但无法进入try中
我想要达到的结果
download改下面这样就行了,保存的文件路径有问题,而且正则也搞错了,objURL,不是ObjURL,搞得没取出路径调试了下,发现大小写写错了,-_-||。。
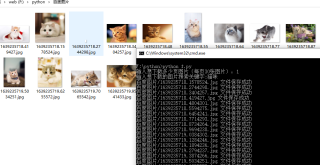
def download(List):
for u in List:
try:
#这里路径有问题,不是图片的问题,由于url中包含其他乱七八糟的路径中不能存在的内容,导致路径出错走了except。用当前时间来命名文件好些
path=root+'/'+str(time.time())+".jpg"
#u = u.replace('\\', '')
r = requests.get(u, timeout=30)
#r.raise_for_status()
#r.encoding = r.apparent_encoding
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(r.content)
f.close()
print(path + ' 文件保存成功')
except:
print(u, "下载失败,可能链接不是指定格式图片")
有帮助麻烦点下【采纳该答案】,谢谢~~