使用scrapy 爬取京东商品名及价格,但是使用CSS并extract() 读不出text.用过scrapy shell 也读出不商品名(我完全是复制的Selector也不行)一直return []
#Create the Spider class
class DC_Description_Spider(scrapy.Spider):
name = "dc_chapter_spider"
# start_requests method
def start_requests(self):
url_short='https://beauty.jd.com/'
yield scrapy.Request(url = url_short, callback = self.parse_front)
# First parsing method
def parse_front(self, response):
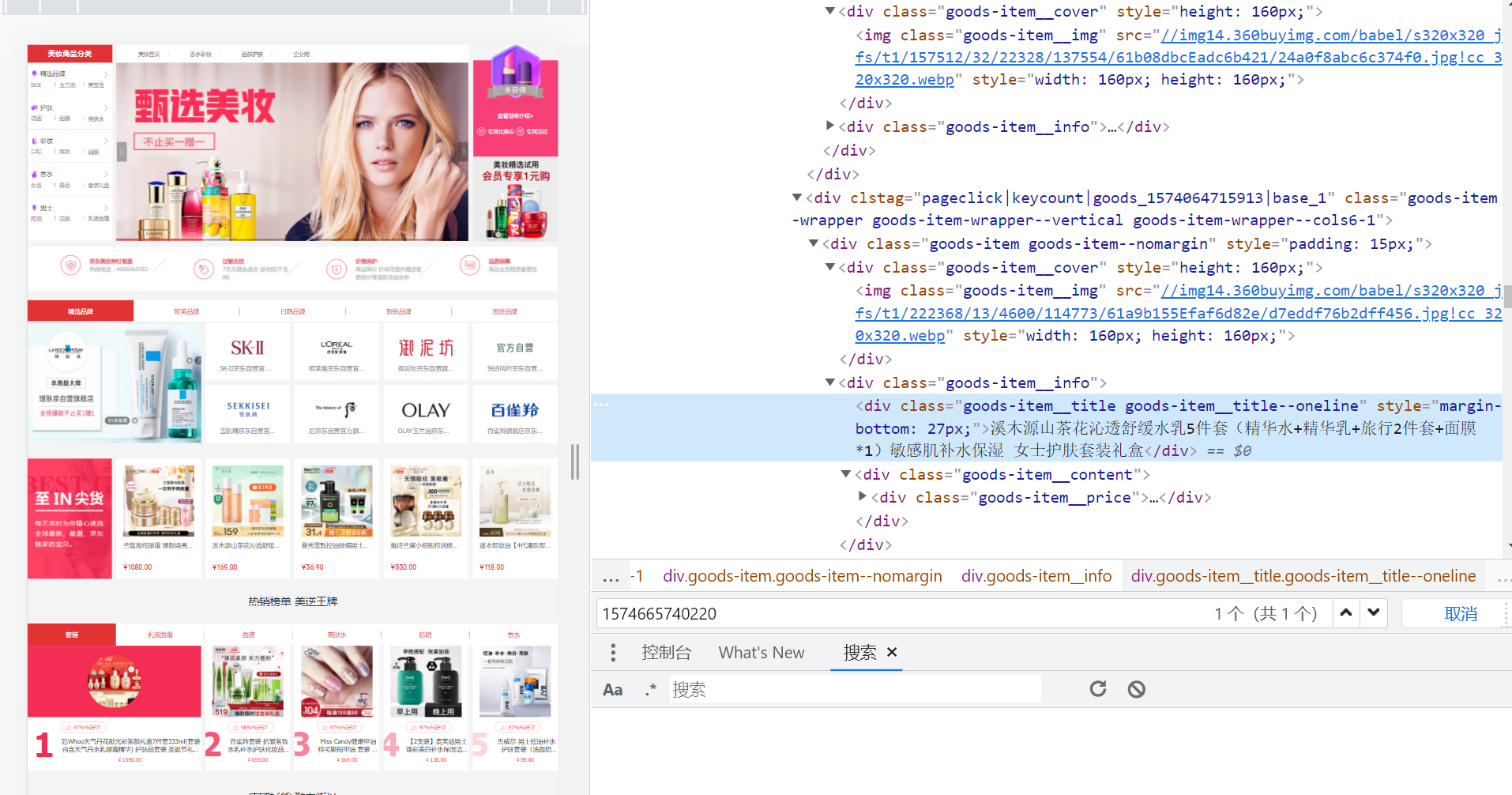
parent_node = response.css('#app > div > div.lc-floor.lc-xfloor--id-1574665740220.lc-floor--lg > div > div:nth-child(9) > div > div > div.lc-nav-tabs__body > div:nth-child(2) > div > div > div')
item_dict=[]
for i in range(4):
item_name = parent_node.css('>div:nth-child({i}) > div > div.goods-item__info > div.goods-item__title.goods-item__title--twoline').extract()
item_price=parent_node.css('>div:nth-child({i}) > div > div.goods-item__info > div.goods-item__content > div').extract()
if item_price == []:
item_price="补货中"
item_dict.append({"name":item_name, "price":item_price})
else:
item_dict.append({"name":item_name, "price":item_price})
return item_dict
#for url in links_to_follow:
#yield response.follow(url = url,
# callback = self.parse_pages)
#Run the spider
process = CrawlerProcess()
process.crawl(DC_Description_Spider)
process.start()
# Print a preview of courses
#previewCourses(dc_dict)
有可能是动态网站的原因。