python如何分割字符串
s='15300120001Will SmithCOMP110033.01A\n15300230125G. WashingtonCOMP110032.02B-\n14300390256Bill GatesCOMP110021.01C+\n'
请问如何分割s得到如图所示的的效果呢?
摸索了大半天了都不对劲。
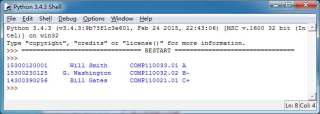
s='15300120001Will SmithCOMP110033.01A\n15300230125G. WashingtonCOMP110032.02B-\n14300390256Bill GatesCOMP110021.01C+\n'
for text in s.split('\n'):
if text:
for value in re.findall("(\d{11})(.*)(COMP\d{6}\.\d{2})([ABC][+-]?)",text):
print value
打印的话可以
import re
s = '15300120001Will SmithCOMP110033.01A\n15300230125G. WashingtonCOMP110032.02B-\n14300390256Bill GatesCOMP110021.01C+\n'
for text in s.split('\n'):
if text:
for value in re.findall("(\d{11})(.*)(COMP\d{6}\.\d{2})([ABC][+-]?)", text):
print '\t'.join(value)
有需要排版对其可以使用format,
import re
s = '15300120001Will SmithCOMP110033.01A\n15300230125G. WashingtonCOMP110032.02B-\n14300390256Bill GatesCOMP110021.01C+\n'
for text in s.split('\n'):
if text:
for value in re.findall("(\d{11})(.*)(COMP\d{6}\.\d{2})([ABC][+-]?)", text):
print "{:<15}{:^20}{:<10}\t{:<10}".format(value[0],value[1],value[2],value[3])
输出的那行的数字可以稍微调整一下,输出大概是
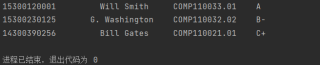
先用 s.split("\n") 分隔,再用正则分隔
import re
s='15300120001Will SmithCOMP110033.01A\n15300230125G. WashingtonCOMP110032.02B-\n14300390256Bill GatesCOMP110021.01C+\n'
res = s.split('\n')
for i in res:
result = re.split(r'(\d{11})(.*(?=COMP))(.*?)', i)
print(result)