UnicodeDecodeError:“gbk”编解码器问题
问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
# -*- coding: utf-8 -*-
"""
Tushare社区股票数据抓取
"""
import urllib.request
import re
import pandas as pd
import pymysql
import os
def getHtml(url):
html = urllib.request.urlopen(url).read()
html = html.decode('gbk')
return html
def getStackCode(html):
s = r'<li><a target="_blank" href="http://quote.eastmoney.com/\S\S(.*?).html">'
pat = re.compile(s)
code = pat.findall(html)
return code
Url = 'http://quote.eastmoney.com/stocklist.html'
filepath = 'C:\\data\\'
code = getStackCode(getHtml(Url))
CodeList = []
for item in code:
if item[0]=='6':
CodeList.append(item)
for code in CodeList:
print('正在获取股票%s数据'%code)
url = 'http://quotes.money.163.com/service/chddata.html?code=0'+code+\
'&end=20161231&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath+code+'.csv')
运行结果及报错内容
Traceback (most recent call last):
File "C:/Python/WorkSpace/py_case/股票数据抓取.py", line 30, in
code = getStackCode(getHtml(Url))
File "C:/Python/WorkSpace/py_case/股票数据抓取.py", line 17, in getHtml
html = html.decode('gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 139: illegal multibyte sequence
我的解答思路和尝试过的方法
我想要达到的结果
题主这个代码从哪搞来的,应该好老了。采集的这个页面已经不存在了,跳转
到http://quote.eastmoney.com/center/gridlist.html#hs_a_board
这个页面,这个页面用的js加载的数据,接口是
http://5.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124009030612137700134_1638235189055&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1638235189056
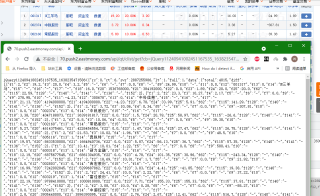
注意是jsonp数据,要处理过才能获取到,不过可以去掉cb=jQuery1124009030612137700134_1638235189055回调参数后返回json数据直接用
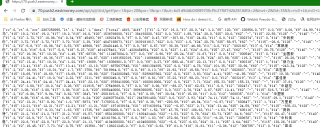
然后直接请求这个接口就行,接口包含了下面的信息,如果要其他信息题主自己通过浏览器开发工具找相关的接口来请求
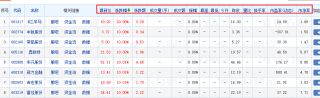
示例代码如下
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
url='http://5.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1638235189056'
data=requests.get(url,headers=headers).json()
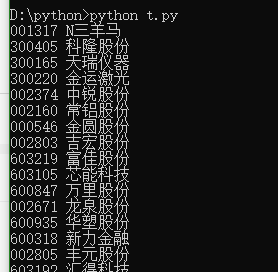
for item in data['data']['diff']:
print(item['f12'],item['f14'])
有帮助麻烦点下【采纳该答案】,谢谢~~有其他问题可以继续交流~
输出print(type(html))的数据类型看看,如果是字节,改utf-8试试
将html = html.decode('gbk')解码改成html = html.decode('unicode-escape'),即可解决不能解码的错误。