读入数据文档Statistic进行统计分析
读入数据文档Statistic进行统计分析,年龄(5岁一档)进行统计,并打印出每个年龄段的人数及数据平均年龄;分别分析男性、女性数据,身高体重(身高区间为10,体重区间为5)二维分布情况,并将男性、女性分析结果分别写去两个文档中。
这个问题的思路是怎么样的
重复代码很多,没有用太复杂的函数和方法,希望你能看懂.有疑问继续交流.有帮助请采纳一下,谢谢
import math
age = {}
nanheight = {}
nvheight = {}
nanweight = {}
nvweight = {}
with open('Statistic', 'r', encoding='utf8') as f:
# 忽略表头
f.readline()
# 读取第二行有效数据
a = f.readline().replace('\n', '')
while a:
# 处理数据转换为元组
a = eval(a.replace(' ', ','))
# print(a)
# 获取年龄段上下线
up = math.ceil(a[0] / 5) * 5
low = (math.ceil(a[0] / 5) - 1) * 5
# 处理年龄数据
key = f"{low}-{up}"
if age.get(key):
age[key][0] += 1
age[key][1] += a[0]
else:
age[key] = [1, a[0]]
# 处理男女升高体重数据 0女1男
if a[1] == 1:
# 获取身高段上下线
up = math.ceil(a[2] / 10) * 10
low = (math.ceil(a[2] / 10) - 1) * 10
key = f"{low}-{up}"
if nvheight.get(key):
nvheight[key] += 1
else:
nvheight[key] = 1
# 获取体重段上下线
up = math.ceil(a[3] / 5) * 5
low = (math.ceil(a[3] / 5) - 1) * 5
key = f"{low}-{up}"
if nanweight.get(key):
nanweight[key] += 1
else:
nanweight[key] = 1
else:
# 获取身高段上下线
up = math.ceil(a[2] / 10) * 10
low = (math.ceil(a[2] / 10) - 1) * 10
key = f"{low}-{up}"
if nanheight.get(key):
nanheight[key] += 1
else:
nanheight[key] = 1
# 获取体重段上下线
up = math.ceil(a[3] / 5) * 5
low = (math.ceil(a[3] / 5) - 1) * 5
key = f"{low}-{up}"
if nvweight.get(key):
nvweight[key] += 1
else:
nvweight[key] = 1
# 读取处理数据替换回车
a = f.readline().replace('\n', '')
for k,v in age.items():
print(k,v[0],v[1]/v[0])
with open('nan.txt','w+',encoding='utf8') as f:
f.write("身高\n")
for k,v in nanheight.items():
f.write(f"{k}:{v}\n")
f.write("体重\n")
for k,v in nanweight.items():
f.write(f"{k}:{v}\n")
with open('nv.txt','w+',encoding='utf8') as f:
f.write("身高\n")
for k,v in nvheight.items():
f.write(f"{k}:{v}\n")
f.write("体重\n")
for k,v in nvweight.items():
f.write(f"{k}:{v}\n")
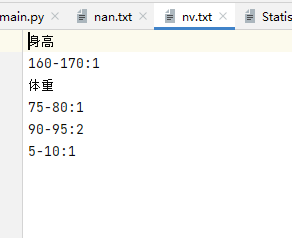
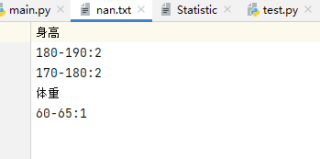
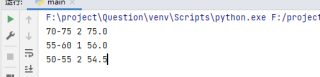
文件读写;
然后 采用 数组 + 字典 的方式应该就可以转换成对应想要的数据结构了