用python requests.post()实现翻页,表单上传后 返回数据缺失
我在爬取一个国外网站遇到的问题?
他的翻页 是动态加载的 每店家下一页 都会多出一个 infinite 请求 俩都是一样的 只能post 来翻页
不知道为什么我的谷歌浏览器看不到表单formdata
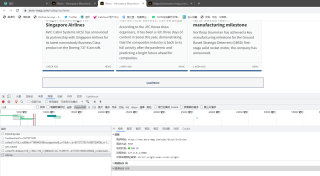
不过还好我用抓包工具 fidder上看到了 真是奇怪??
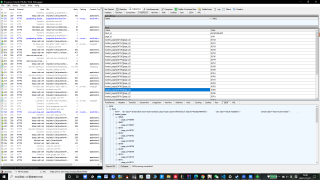
然后就用post提交表单想要达到翻页的效果 但是返回的data是无的 跟我想象的不一样??
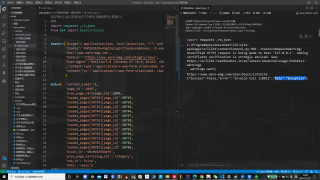
这是代码
import requests ,re,json
from bs4 import BeautifulSoup
header={'Accept':'application/json, text/javascript, */*; q=0.01',
'Cookie':'PHPSESSID=95gf2q2rglsttoeimvsqb4saar; cb-enabled=enabled; _ga=GA1.2.1766498299.1637376336; _gid=GA1.2.852145304.1637376336; _gat_gtag_UA_11280151_1=1',
'Hos':'www.aero-mag.com',
'Referer':'https://www.aero-mag.com/category/news',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
,'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Content-Typ':'application/x-www-form-urlencoded; charset=UTF-8'
}
body={ 'current_loads':1,
'page_id':'1049',
'psas_page_vars[page_id]':1049,
'loaded_pages[38729][page_id]':38729,
'loaded_pages[38734][page_id]':38734,
'loaded_pages[38736][page_id]':38736,
'loaded_pages[38744][page_id]':38744,
'loaded_pages[38757][page_id]':38757,
'loaded_pages[38758][page_id]':38758,
'loaded_pages[38759][page_id]':38759,
'loaded_pages[38761][page_id]':38761,
'loaded_pages[38766][page_id]':38766,
'loaded_pages[38773][page_id]':38773,
'loaded_pages[38782][page_id]':38782,
'loaded_pages[38783][page_id]':38783,
'block_id':'60c0d24964ef3',
'psas_page_vars[slug_id]':'category',
'tab_id':'false',
'Data':'valuy'}
url='https://www.aero-mag.com/ajax/block/infinite'
data1=requests.post(url,data=json.dumps(body),headers=header,verify=False)
print(data1.url)
print(data1.text)
难道是我表单错误了吗??
我看了一遍没有呀
Content-Typ':'application/x-www-form-urlencoded; charset=UTF-8'
是对应data 的呀 没错误
我只是想要简单的翻页,这给我整不会了,导师不让我用selenium自动化点击 ,说太慢了,看来只能用requests 的post了?或者用别的什么库 scrapy 我还安装错误了目前还没搞懂?
i need help help
1.需要传cookies参数,2.data数据的即字典的值都要写成字符串。获取json后再从中用bs4解析出数据。
参考如下代码:
import requests
cookies = {
'PHPSESSID': 'nvd3sfboq2s3o3dl97pp6s15l6',
'cb-enabled': 'enabled',
'_ga': 'GA1.2.774400005.1638014126',
'_gid': 'GA1.2.940028981.1638014126',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'csrftoken': 'd71877461a0e180bf4b60a082c0cbb3abcfec87cfc0d99fdcdf3200ac69af5db',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'https://www.aero-mag.com/category/news',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
data = {
'block_id': '60c0d24964ef3',
'page_id': '1049',
'loaded_pages[38773][page_id]': '38773',
'loaded_pages[38782][page_id]': '38782',
'loaded_pages[38783][page_id]': '38783',
'loaded_pages[38785][page_id]': '38785',
'loaded_pages[38790][page_id]': '38790',
'loaded_pages[38791][page_id]': '38791',
'loaded_pages[38794][page_id]': '38794',
'loaded_pages[38797][page_id]': '38797',
'loaded_pages[38800][page_id]': '38800',
'loaded_pages[38801][page_id]': '38801',
'loaded_pages[38806][page_id]': '38806',
'loaded_pages[38810][page_id]': '38810',
'tab_id': 'false',
'current_loads': '1',
'psas_page_vars[0]': 'news',
'psas_page_vars[page_id]': '1049',
'psas_page_vars[slug_id]': 'category'
}
response = requests.post('https://www.aero-mag.com/ajax/block/infinite',
headers=headers, cookies=cookies, data=data)
print(response.json())
如有帮助,请点采纳。