python爬虫爬取不到数据,如何分析定位?
问题遇到的现象和发生背景
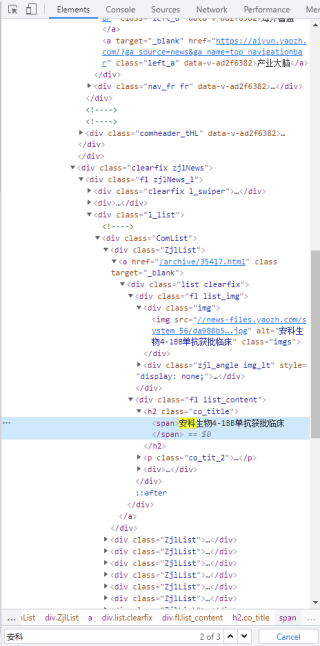
爬虫,定位elements中的标签后爬取不到数据
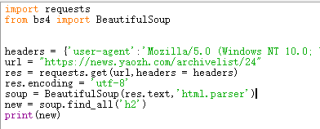
问题相关代码,请勿粘贴截图
运行结果及报错内容
运行后返回空列表
我的解答思路和尝试过的方法
尝试过定位h2标签中的class_=co_title,或者直接定义span标签,也不能提取到数据。
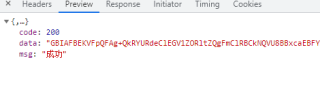
另:该网页的network中没有网页的数据,都是一长串字母,数据在elements中能找到。(这个是什么原因,看了很多例子打开preview就能看到网页的内容的)
我想要达到的结果
想到提取每日的新闻内容和时间,内容在h2 class_=co_title中,时间在class_=co_name中
你爬虫应该是用requests发送http请求的吧,这个是无法从elements找到,你要在network的doc分析网页,你找不到的数据很大可能是ajax请求渲染前端的
试试xpath,选中节点后右击复制xpath,在程序用xpath来定位元素,定位到后就可以获取数据了
你使用pycharm的调试功能,看看每一步的结果是不是正确的