1
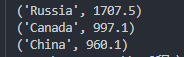
li = [('Russia',1707.5),('China',960.1),('Canada',997.1)]
li.sort(key=lambda x: x[1], reverse=True)
for t in li:
print(t)
2
e_dict = {'name':'zyw','number':'001','tal':18870019127}
print(e_dict['name'],e_dict['number'],e_dict['tal'])
print(e_dict.items())
print(e_dict.keys())
print(e_dict.values())
print(e_dict.get('name'))

3
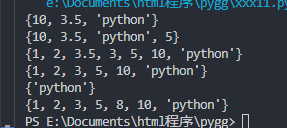
a_set = {10,"python",3.5}
print(a_set)
a_set.add(5)
print(a_set)
a_set.update([1,2,3])
print(a_set)
a_set.remove(3.5)
print(a_set)
b_set = {8,"python"}
print(a_set & b_set)
print(a_set | b_set)
4
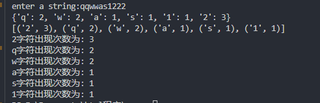
s = input("enter a string:")
dic = {}
for v in s:
dic[v] = dic.get(v,0)+1
print(dic)
li = sorted(dic.items(),key=lambda x: x[1])
print(li)
for c,v in li:
print(f'{c}字符出现次数为: {v}')
5
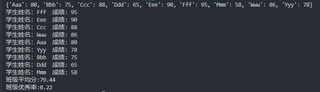
dic = {"Aaa":80,"Bbb":75,"Ccc":88,"Ddd":65,"Eee":90,"Fff":95,"Mmm":58,"Www":86,"Yyy":78}
print(dic)
li = sorted(dic.items(),key=lambda x: x[1], reverse=True)
for c,v in li:
print(f'学生姓名:{c} 成绩: {v}')
print(f'班级平均分:{sum(dic.values())/len(dic) :.2f}')
print(f'班级优秀率:{len([x for x in dic.values() if x>=90])/len(dic) :.2}')